Una nota de Google filtrada proporciona un resumen punto por punto de por qué Google está perdiendo terreno frente a la IA de código abierto y sugiere un camino de regreso al dominio y la propiedad de la plataforma.
La nota abre reconociendo que su competidor nunca ha sido OpenAI y siempre será Open Source.
No pueden competir con Open Source
Además, admiten que de ninguna manera están posicionados para competir con el código abierto y admiten que ya han perdido la batalla por el dominio de la IA.
Ellos escribieron:
«Hemos estado mirando mucho detrás de OpenAI. ¿Quién cruzará el próximo hito? ¿Cuál será el próximo paso?
Pero la verdad incómoda es que no estamos en condiciones de ganar esta carrera armamentista, y OpenAI tampoco. Mientras discutíamos, una tercera facción comía tranquilamente nuestro almuerzo.
Estoy hablando, por supuesto, de código abierto.
Claramente, nos ganaron. Las cosas que consideramos ‘principales preguntas abiertas’ se están resolviendo y están en manos de la gente hoy».
La mayor parte del aviso se dedica a describir cómo Google está siendo superado por el código abierto.
Y aunque Google tiene una ligera ventaja en código abierto, el autor del memorando admite que se está escapando y nunca volverá.
El autoanálisis de las cartas metafóricas que ellos mismos repartieron es notablemente desfavorable:
“Aunque nuestros modelos aún mantienen una ligera ventaja en términos de calidad, la brecha se está cerrando sorprendentemente rápido.
Los modelos de código abierto son más rápidos, más personalizables, más privados y con mayor capacidad libra por libra.
Están haciendo cosas con parámetros de $ 100 y $ 13 mil millones con los que estamos luchando en $ 10 millones y $ 540 mil millones.
Y lo hacen en semanas, no en meses.
El gran tamaño del modelo de lengüeta no es una ventaja
Quizás la realización más aterradora expresada en la nota es que el tamaño de Google ya no es un activo.
Los tamaños extraordinariamente grandes de sus modelos ahora se ven como desventajas y no como la ventaja insuperable que alguna vez se pensó que eran.
El memorando filtrado enumera una serie de eventos que indican que el control de Google (y OpenAI) sobre la IA podría terminar rápidamente.
Se dice que hace apenas un mes, en marzo de 2023, la comunidad de código abierto obtuvo un modelo de código abierto filtrado, un gran modelo de lenguaje desarrollado por Meta, llamado LLaMA.
En días y semanas, la comunidad global de código abierto desarrolló todos los componentes básicos necesarios para crear clones de Bard y ChatGPT.
Pasos sofisticados como la optimización de instrucciones y el aprendizaje por refuerzo de retroalimentación humana (RLHF) fueron replicados rápidamente por la comunidad global de código abierto, no menos económicamente.
- Ajuste de instrucciones
Un proceso de ajuste fino de un modelo de lenguaje para que haga algo específico para lo que no fue entrenado originalmente. - Aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF)
Una técnica en la que los humanos evalúan un idioma da forma a la salida para aprender qué salidas son satisfactorias para los humanos.
RLHF es la técnica utilizada por OpenAI para crear InstructGPT, que es un modelo que sustenta a ChatGPT y permite que los modelos GPT-3.5 y GPT-4 reciban instrucciones y completen tareas.
RLHF es el fuego del que despegó el código abierto
El alcance de las fuentes abiertas asusta a Google
Lo que asusta particularmente a Google es que el movimiento de código abierto pueda expandir sus proyectos de una manera que el código cerrado no puede.
El conjunto de datos de preguntas y respuestas utilizado para crear el clon de ChatGPT de código abierto, Dolly 2.0, fue creado en su totalidad por miles de voluntarios dedicados.
Google y OpenAI se basaron en parte en preguntas y respuestas en sitios como Reddit.
Se afirma que el conjunto de datos de preguntas y respuestas de código abierto creado por Databricks es de mayor calidad porque las personas que contribuyeron a su creación eran profesionales y las respuestas proporcionadas fueron más largas y más sustantivas que las que se encuentran en un conjunto típico de datos de preguntas y respuestas. tomado de un foro público.
La nota filtrada señaló:
“A principios de marzo, la comunidad de código abierto consiguió el primer modelo base verdaderamente capaz cuando LLaMA de Meta se lanzó al público.
No tenía instrucciones ni sintonización de conversación ni RLHF.
La comunidad, sin embargo, comprendió de inmediato el significado de lo que se les dio.
Se produjo un extraordinario estallido de innovación, con solo unos pocos días entre los principales desarrollos…
Aquí estamos, solo un mes después, y hay variantes con ajuste de instrucciones, cuantificación, mejora de la calidad, evaluaciones humanas, multimodo, RLHF, etc. muchos de ellos se construyen unos sobre otros.
Lo más importante es que han resuelto el problema de escalado en la medida en que cualquiera puede manejarlo.
Muchas de las nuevas ideas provienen de la gente común.
La barrera de entrada para la capacitación y las pruebas se ha reducido de la producción total de una importante organización de investigación a una persona, una noche y una computadora portátil resistente.
En otras palabras, lo que tomó meses y años para que Google y OpenAI entrenaran y construyeran, tomó solo días para la comunidad de código abierto.
Este debe ser un escenario realmente aterrador para Google.
Es una de las razones por las que he escrito tanto sobre el movimiento de IA de código abierto, porque realmente muestra dónde estará el futuro de la IA generativa en un período de tiempo relativamente corto.
El código abierto ha superado históricamente al código cerrado
La nota cita la experiencia reciente con DALL-E de OpenAI, el modelo de aprendizaje profundo utilizado para crear imágenes en comparación con el Stable Diffusion de código abierto, como un presagio de lo que está sucediendo ahora con la IA generativa como Bard y ChatGPT.
OpenAI lanzó Dall-e en enero de 2021. Stable Diffusion, la versión de código abierto, se lanzó un año y medio después, en agosto de 2022, y en cuestión de semanas superó a Dall-E en popularidad.
Esta línea de tiempo muestra la rapidez con la que Stable Diffusion superó a Dall-E:
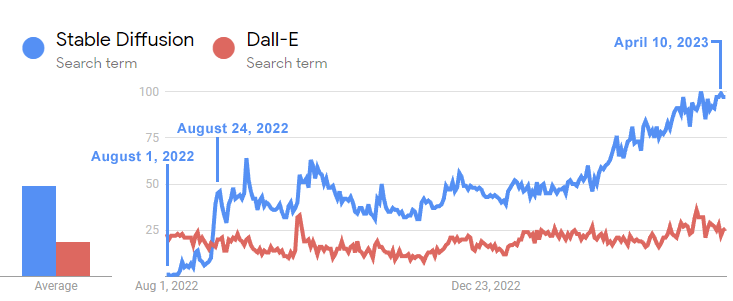
La línea de tiempo de Google Trends anterior muestra cómo el interés en el modelo de difusión estable de código abierto superó con creces al de Dall-E dentro de las tres semanas posteriores a su lanzamiento.
Y aunque Dall-E ha estado fuera durante un año y medio, el interés en Stable Diffusion ha seguido creciendo exponencialmente, mientras que Dall-E de OpenAI ha permanecido estancado.
La amenaza existencial de eventos similares que envuelven a Bard (y OpenAI) le da pesadillas a Google.
El proceso de creación de modelos Open Source es superior
Otro factor que preocupa a los ingenieros de Google es que el proceso de creación y mejora de modelos de código abierto es rápido, económico y se presta perfectamente a un enfoque colaborativo global común a los proyectos de código abierto.
La nota señala que las nuevas técnicas como LoRA (Adaptación de bajo rango de modelos de lenguaje grande) permiten ajustar los modelos de lenguaje en días a un costo extremadamente bajo, con el LLM final comparable a los LLM extremadamente costosos. creado por Google y OpenAI.
Otro beneficio es que los ingenieros de código abierto pueden basarse en el trabajo anterior iterando en lugar de tener que empezar desde cero.
No es necesario construir grandes modelos de lenguaje con miles de millones de parámetros como lo hicieron hoy OpenAI y Google.
Este puede ser el punto que Sam Alton estaba señalando cuando dijo recientemente que la era de los modelos de lenguaje masivo ha terminado.
El autor de la alerta de Google contrastó el enfoque económico y rápido de LoRA para construir LLM con el enfoque actual de gran inteligencia artificial.
El autor del memo reflexiona sobre la falta de Google:
“En cambio, entrenar modelos gigantes desde cero no solo destruye el entrenamiento previo, sino también cualquier mejora iterativa que se haya realizado. hecho además. En el mundo del código abierto, estas mejoras no tardan mucho en prevalecer, lo que hace que una remodelación completa sea extremadamente costosa.
Debemos tener cuidado si cada nueva aplicación o idea realmente necesita un modelo completamente nuevo.
… De hecho, en términos de horas de ingeniería, el ritmo de mejora de estos modelos supera con creces lo que podemos hacer con nuestras variantes más grandes, y las mejores ya son en gran medida indistinguibles de ChatGPT.
El autor concluye dándose cuenta de que lo que pensaban que era su ventaja, sus proyectos gigantescos y el costo prohibitivo concomitante, en realidad era una desventaja.
La naturaleza colaborativa global de Open Source es más eficiente y más rápida para innovar.
¿Cómo puede un sistema de código cerrado competir con la abrumadora multitud de ingenieros de todo el mundo?
El autor concluye que no pueden competir y que la competencia directa es, en sus palabras, una «proposición perdedora».
Esta es la crisis, la tormenta que se está gestando fuera de Google.
Si no puedes vencer al código abierto, únete a ellos
El único consuelo que encuentra el autor del memorando en el código abierto es que, debido a que la innovación de código abierto es gratuita, Google también puede beneficiarse.
En última instancia, el autor concluye que el único enfoque de Google es poseer la plataforma de la misma manera que domina las plataformas de código abierto Chrome y Android.
Señalan cómo Meta se está beneficiando del lanzamiento de su modelo de lenguaje grande LLaMA para la investigación y cómo ahora tienen a miles de personas haciendo su trabajo de forma gratuita.
Quizás la gran conclusión del memorando es que Google puede, en un futuro cercano, intentar replicar su dominio de código abierto lanzando proyectos de código abierto y luego siendo dueño de la plataforma.
La nota concluye que usar código abierto es la opción más viable:
“Google debería establecerse como líder en la comunidad de código abierto, tomando la iniciativa colaborando con, en lugar de ignorar, la conversación más amplia.
Esto probablemente signifique tomar algunos pasos incómodos, como publicar los pesos de los modelos para las variantes pequeñas de ULM. Esto necesariamente significa renunciar a cierto control sobre nuestros modelos.
Pero este compromiso es inevitable.
No podemos aspirar a liderar la innovación y controlarla».
El código abierto despega con el fuego de la IA
La semana pasada abordamos el mito griego del héroe humano Prometeo robando el fuego de los dioses en el Monte Olimpo, enfrentando al Prometeo de código abierto contra los «dioses olímpicos» de Google y OpenAI:
«Mientras que Google, Microsoft y Open AI están discutiendo entre sí y de espaldas, ¿Open Source toma las decisiones?»
La filtración del memorando de Google confirma esta observación, pero también apunta a un posible cambio en la estrategia de Google para unirse al movimiento de código abierto y luego cooptarlo y dominarlo de la misma manera que lo han hecho con Chrome y Android.
Lea la nota de Google filtrada aquí:
Fuente: searchenginejournal
Hashtags: #Nota #filtrada #Google #reconoce #derrota #código #abierto
Comentarios recientes