Researchers tested the idea that an AI model may have an advantage in self-detecting its own content because the detection was leveraging the same training and datasets. What they didn’t expect to find was that out of the three AI models they tested, the content generated by one of them was so undetectable that even the AI that generated it couldn’t detect it.
The study was conducted by researchers from the Department of Computer Science, Lyle School of Engineering at Southern Methodist University.
AI Content Detection
Many AI detectors are trained to look for the telltale signals of AI generated content. These signals are called “artifacts” which are generated because of the underlying transformer technology. But other artifacts are unique to each foundation model (the Large Language Model the AI is based on).
These artifacts are unique to each AI and they arise from the distinctive training data and fine tuning that is always different from one AI model to the next.
The researchers discovered evidence that it’s this uniqueness that enables an AI to have a greater success in self-identifying its own content, significantly better than trying to identify content generated by a different AI.
Bard has a better chance of identifying Bard-generated content and ChatGPT has a higher success rate identifying ChatGPT-generated content, but…
The researchers discovered that this wasn’t true for content that was generated by Claude. Claude had difficulty detecting content that it generated. The researchers shared an idea of why Claude was unable to detect its own content and this article discusses that further on.
This is the idea behind the research tests:
“Since every model can be trained differently, creating one detector tool to detect the artifacts created by all possible generative AI tools is hard to achieve.
Here, we develop a different approach called self-detection, where we use the generative model itself to detect its own artifacts to distinguish its own generated text from human written text.
This would have the advantage that we do not need to learn to detect all generative AI models, but we only need access to a generative AI model for detection.
This is a big advantage in a world where new models are continuously developed and trained.”
Methodology
The researchers tested three AI models:
- ChatGPT-3.5 by OpenAI
- Bard by Google
- Claude by Anthropic
All models used were the September 2023 versions.
A dataset of fifty different topics was created. Each AI model was given the exact same prompts to create essays of about 250 words for each of the fifty topics which generated fifty essays for each of the three AI models.
Each AI model was then identically prompted to paraphrase their own content and generate an additional essay that was a rewrite of each original essay.
They also collected fifty human generated essays on each of the fifty topics. All of the human generated essays were selected from the BBC.
The researchers then used zero-shot prompting to self-detect the AI generated content.
Zero-shot prompting is a type of prompting that relies on the ability of AI models to complete tasks for which they haven’t specifically trained to do.
The researchers further explained their methodology:
“We created a new instance of each AI system initiated and posed with a specific query: ‘If the following text matches its writing pattern and choice of words.’ The procedure is
repeated for the original, paraphrased, and human essays, and the results are recorded.We also added the result of the AI detection tool ZeroGPT. We do not use this result to compare performance but as a baseline to show how challenging the detection task is.”
They also noted that a 50% accuracy rate is equal to guessing which can be regarded as essentially a level of accuracy that is a failure.
Results: Self-Detection
It must be noted that the researchers acknowledged that their sample rate was low and said that they weren’t making claims that the results are definitive.
Below is a graph showing the success rates of AI self-detection of the first batch of essays. The red values represent the AI self-detection and the blue represents how well the AI detection tool ZeroGPT performed.
Results Of AI Self-Detection Of Own Text Content
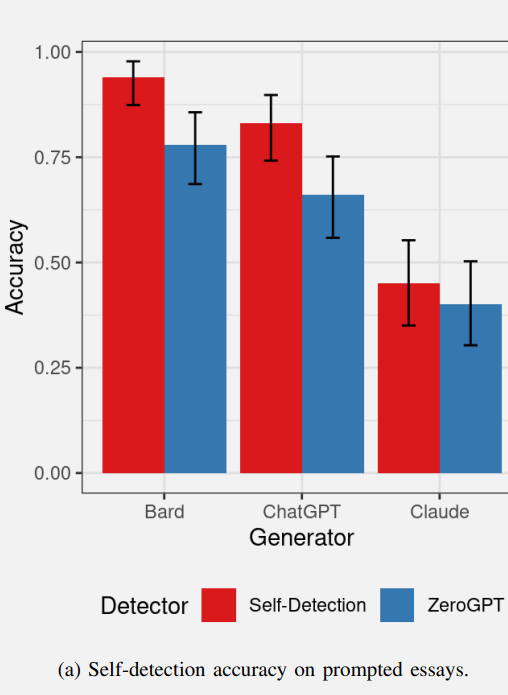
Bard did fairly well at detecting its own content and ChatGPT also performed similarly well at detecting its own content.
ZeroGPT, the AI detection tool detected the Bard content very well and performed slightly less better in detecting ChatGPT content.
ZeroGPT essentially failed to detect the Claude-generated content, performing worse than the 50% threshold.
Claude was the outlier of the group because it was unable to to self-detect its own content, performing significantly worse than Bard and ChatGPT.
The researchers hypothesized that it may be that Claude’s output contains less detectable artifacts, explaining why both Claude and ZeroGPT were unable to detect the Claude essays as AI-generated.
So, although Claude was unable to reliably self-detect its own content, that turned out to be a sign that the output from Claude was of a higher quality in terms of outputting less AI artifacts.
ZeroGPT performed better at detecting Bard-generated content than it did in detecting ChatGPT and Claude content. The researchers hypothesized that it could be that Bard generates more detectable artifacts, making Bard easier to detect.
So in terms of self-detecting content, Bard may be generating more detectable artifacts and Claude is generating less artifacts.
Results: Self-Detecting Paraphrased Content
The researchers hypothesized that AI models would be able to self-detect their own paraphrased text because the artifacts that are created by the model (as detected in the original essays) should also be present in the rewritten text.
However the researchers acknowledged that the prompts for writing the text and paraphrasing are different because each rewrite is different than the original text which could consequently lead to a different self-detection results for the self-detection of paraphrased text.
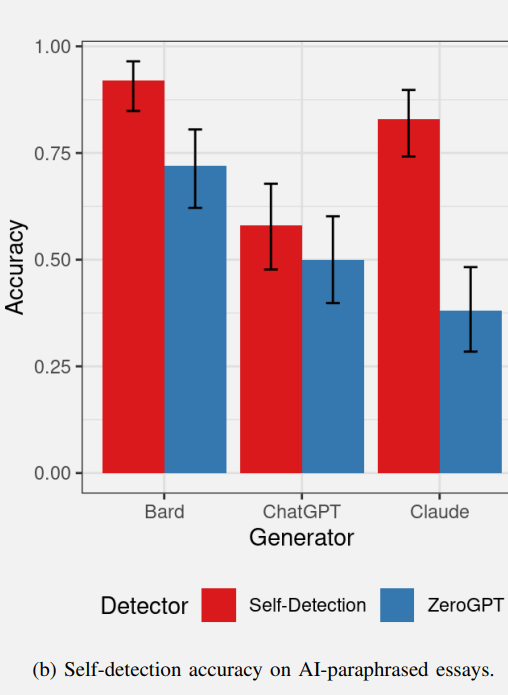
The results of the self-detection of paraphrased text was indeed different from the self-detection of the original essay test.
- Bard was able to self-detect the paraphrased content at a similar rate.
- ChatGPT was not able to self-detect the paraphrased content at a rate much higher than the 50% rate (which is equal to guessing).
- ZeroGPT performance was similar to the results in the previous test, performing slightly worse.
Perhaps the most interesting result was turned in by Anthropic’s Claude.
Claude was able to self-detect the paraphrased content (but it was not able to detect the original essay in the previous test).
It’s an interesting result that Claude’s original essays apparently had so few artifacts to signal that it was AI generated that even Claude was unable to detect it.
Yet it was able to self-detect the paraphrase while ZeroGPT could not.
The researchers remarked on this test:
“The finding that paraphrasing prevents ChatGPT from self-detecting while increasing Claude’s ability to self-detect is very interesting and may be the result of the inner workings of these two transformer models.”
Screenshot of Self-Detection of AI Paraphrased Content
These tests yielded almost unpredictable results, particularly with regard to Anthropic’s Claude and this trend continued with the test of how well the AI models detected each others content, which had an interesting wrinkle.
Results: AI Models Detecting Each Other’s Content
The next test showed how well each AI model was at detecting the content generated by the other AI models.
If it’s true that Bard generates more artifacts than the other models, will the other models be able to easily detect Bard-generated content?
The results show that yes, Bard-generated content is the easiest to detect by the other AI models.
Regarding detecting ChatGPT generated content, both Claude and Bard were unable to detect it as AI-generated (justa as Claude was unable to detect it).
ChatGPT was able to detect Claude-generated content at a higher rate than both Bard and Claude but that higher rate was not much better than guessing.
The finding here is that all of them weren’t so good at detecting each others content, which the researchers opined may show that self-detection was a promising area of study.
Here is the graph that shows the results of this specific test:
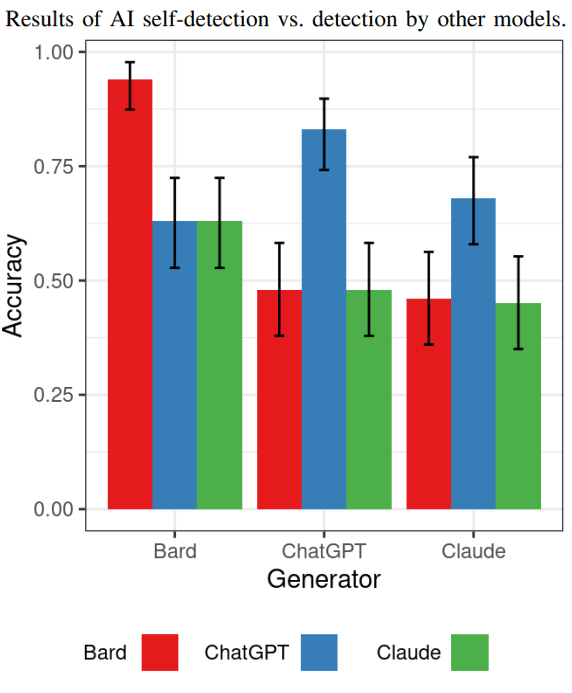
At this point it should be noted that the researchers don’t claim that these results are conclusive about AI detection in general. The focus of the research was testing to see if AI models could succeed at self-detecting their own generated content. The answer is mostly yes, they do a better job at self-detecting but the results are similar to what was found with ZEROGpt.
The researchers commented:
“Self-detection shows similar detection power compared to ZeroGPT, but note that the goal of this study is not to claim that self-detection is superior to other methods, which would require a large study to compare to many state-of-the-art AI content detection tools. Here, we only investigate the models’ basic ability of self detection.”
Conclusions And Takeaways
The results of the test confirm that detecting AI generated content is not an easy task. Bard is able to detect its own content and paraphrased content.
ChatGPT can detect its own content but works less well on its paraphrased content.
Claude is the standout because it’s not able to reliably self-detect its own content but it was able to detect the paraphrased content, which was kind of weird and unexpected.
Detecting Claude’s original essays and the paraphrased essays was a challenge for ZeroGPT and for the other AI models.
The researchers noted about the Claude results:
“This seemingly inconclusive result needs more consideration since it is driven by two conflated causes.
1) The ability of the model to create text with very few detectable artifacts. Since the goal of these systems is to generate human-like text, fewer artifacts that are harder to detect means the model gets closer to that goal.
2) The inherent ability of the model to self-detect can be affected by the used architecture, the prompt, and the applied fine-tuning.”
The researchers had this further observation about Claude:
“Only Claude cannot be detected. This indicates that Claude might produce fewer detectable artifacts than the other models.
The detection rate of self-detection follows the same trend, indicating that Claude creates text with fewer artifacts, making it harder to distinguish from human writing”.
But of course, the weird part is that Claude was also unable to self-detect its own original content, unlike the other two models which had a higher success rate.
The researchers indicated that self-detection remains an interesting area for continued research and propose that further studies can focus on larger datasets with a greater diversity of AI-generated text, test additional AI models, a comparison with more AI detectors and lastly they suggested studying how prompt engineering may influence detection levels.
Read the original research paper and the abstract here:
AI Content Self-Detection for Transformer-based Large Language Models
Featured Image by Shutterstock/SObeR 9426
Fuente: searchenginejournal
Hashtags: #Bard #ChatGPT #Claude
Comentarios recientes