Estudiar a desarrollar, así sea con Python, JavaScript u otro lenguaje de programación, tiene un sinnúmero de provecho, incluyendo la aptitud de trabajar con conjuntos de datos mucho más enormes y hacer de manera automática tareas repetitivas.
Pero pese a las ventajas, varios expertos de SEO aún deben llevar a cabo la transición, ¡y comprendo absolutamente por qué razón! No es una capacidad SEO fundamental y todos somos personas ocupadas.
Si tiene poco tiempo y ahora sabe de qué forma llenar una labor en Excel u Hojas de cálculo de Google plus, cambiar su estilo puede ser como reinventar la rueda.
En el momento en que empecé a desarrollar, en un inicio solo utilizaba Python para tareas que no podía llevar a cabo en Excel, y me tomó ciertos años llegar al punto en que es mi decisión de hecho para el procesamiento de datos.
Viendo hacia atrás, estoy impresionantemente contento de haber persistido, pero en ocasiones fue una experiencia desepcionante, con muchas horas dedicadas a escanear hilos en Stack Overflow.
Esta publicación está desarrollada para socorrer a otros expertos de SEO del mismo destino.
En él, cubriremos los equivalentes de Python de las fórmulas y funcionalidades de Excel mucho más usadas para el análisis de datos de SEO, todas y cada una libres en un cuaderno de Google plus Colab relacionado en el resumen.
Particularmente, va a aprender los equivalentes de:
- LEN.
- Remover repetidos.
- Artículo de columna.
- BUSCAR/ENCONTRAR.
- LINO.
- Conseguir y sustituir.
- IZQUIERDA CENTRO DERECHA.
- UNO MISMO.
- extensión de ifs.
- BUSCAR V.
- CONTAR.SI/SUMAR.SI/PROMEDIO.SI.
- Tablas dinamicas.
Increíblemente, para poder todo lo mencionado, vamos a usar eminentemente solo una biblioteca: Panda – con algo de asistencia aquí y allí del hermano mayor, entumecido.
requisitos anteriores
En labras de la brevedad, existen algunas cosas que no cubriremos el día de hoy, que tienen dentro:
- Instalación de Python.
- Pandas básicos como importar ficheros CSV, filtrar y previsualizar marcos de datos.
Si no está seguro sobre alguno de estos, la Guía de Hamlet para el análisis de datos de Python para SEO es la introducción impecable.
En este momento, sin más ni más preámbulos, pongámonos manos a la obra.
LARGO
LEN da un recuento del número de letras y números en una cadena de artículo.
Para SEO particularmente, un caso de empleo común es medir la longitud de las etiquetas de título o misión especificaciones para saber si se truncarán en los resultados de la búsqueda.
En Excel, si quisiéramos contar la segunda celda de la columna A, ingresaríamos:
=LEN(A2)
-
 Atrapa de pantalla de Microsoft Excel, noviembre de 2022
Atrapa de pantalla de Microsoft Excel, noviembre de 2022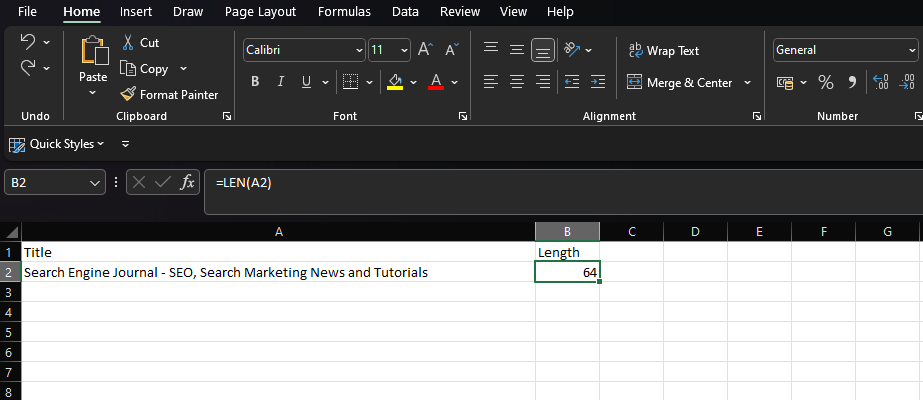
Python no es muy distinta, puesto que tenemos la posibilidad de confiar en la función len incorporada, que se puede conjuntar con la localización de pandas.[] para entrar a una fila concreta de datos en una columna:
len(df['Title'].loc[0])
En este caso de ejemplo, conseguimos la longitud de la primera fila en la columna «Título» del marco de datos.


- Atrapa de pantalla de VS Code, noviembre de 2022
No obstante, conseguir la longitud de una celda no es realmente útil para SEO. ¡Comunmente, nos agradaría utilizar una función a una columna completa!
En Excel, esto se haría escogiendo la celda de fórmula en la esquina inferior derecha y arrastrándola hacia abajo o realizando doble click en ella.
En el momento en que estamos trabajando con un marco de datos de pandas, tenemos la posibilidad de utilizar str.len para calcular la longitud de las filas en una matriz y después guardar los desenlaces en una exclusiva columna:
df['Length'] = df['Title'].str.len()
Str.len es una operación «vectorizada» desarrollada para aplicarse a múltiples valores al unísono. Vamos a usar estas operaciones extensamente en el artículo por el hecho de que prácticamente universalmente acaban siendo mucho más veloces que un bucle.
Otra app común de LEN es combinarlo con SUBSTITUTE para contar el número de expresiones en una celda:
=LEN(TRIM(A2))-LEN(SUBSTITUTE(A2," ",""))+1
En Pandas, tenemos la posibilidad de conseguir esto mezclando las funcionalidades str.split y str.len juntas:
df['No. Words'] = df['Title'].str.split().str.len()
Vamos a hablar de str.split con mucho más aspecto mucho más adelante, pero fundamentalmente lo que hacemos es dividir nuestros apuntes por el espacio en blanco en la cadena y después contar el número de elementos.
-
 Atrapa de pantalla de VS Code, noviembre de 2022
Atrapa de pantalla de VS Code, noviembre de 2022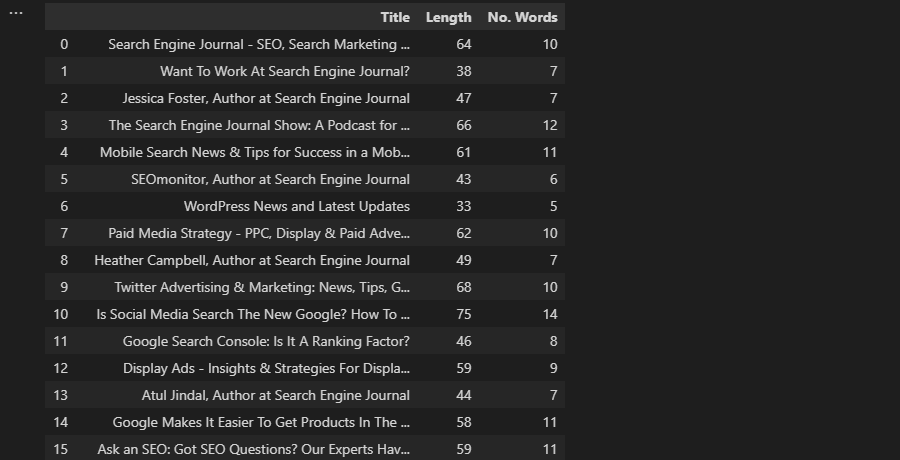
Remover repetidos
La función «Remover repetidos» de Excel da una forma simple de remover valores repetidos de un grupo de datos, así sea descartando filas repetidas completamente (en el momento en que se escogen todas y cada una de las columnas) o descartando filas con exactamente los mismos valores en columnas concretas.
-
 Atrapa de pantalla de Microsoft Excel, noviembre de 2022
Atrapa de pantalla de Microsoft Excel, noviembre de 2022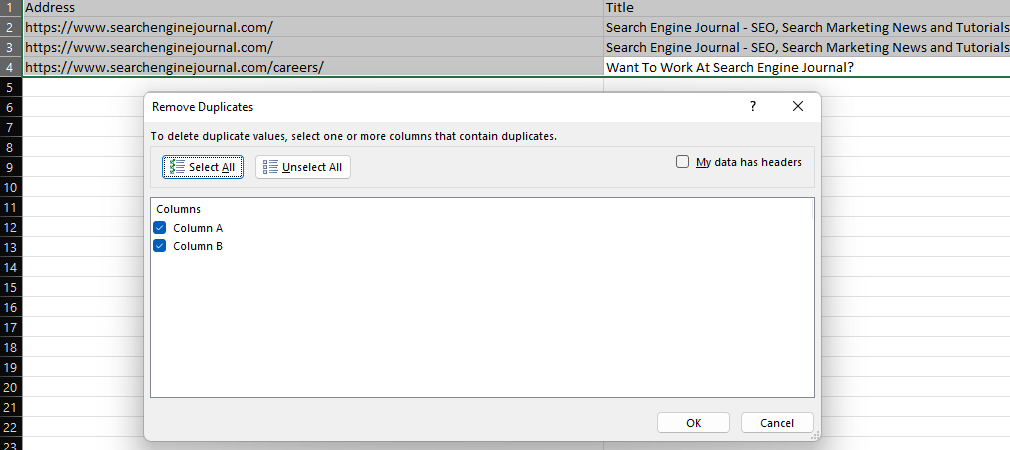
En Pandas, drop_duplicates da esta ocupación.
Para remover filas repetidas en un género de marco de datos:
df.drop_duplicates(inplace=True)
Para remover filas fundamentadas en repetidos en solo una columna, integre el factor de subconjunto:
df.drop_duplicates(subset="column", inplace=True)
O especifique múltiples columnas en una lista:
df.drop_duplicates(subset=['column','column2'], inplace=True)
Una adición previo que merece la pena nombrar es la presencia del factor inplace. Integrar inplace=True nos deja sobrescribir el marco de datos que existe sin la necesidad de hacer uno nuevo.
Por supuesto, hay oportunidades en las que deseamos preservar nuestros apuntes sin procesar. En un caso así, tenemos la posibilidad de conceder el marco de datos deduplicados a una variable diferente:
df2 = df.drop_duplicates(subset="column")
Artículo en columnas
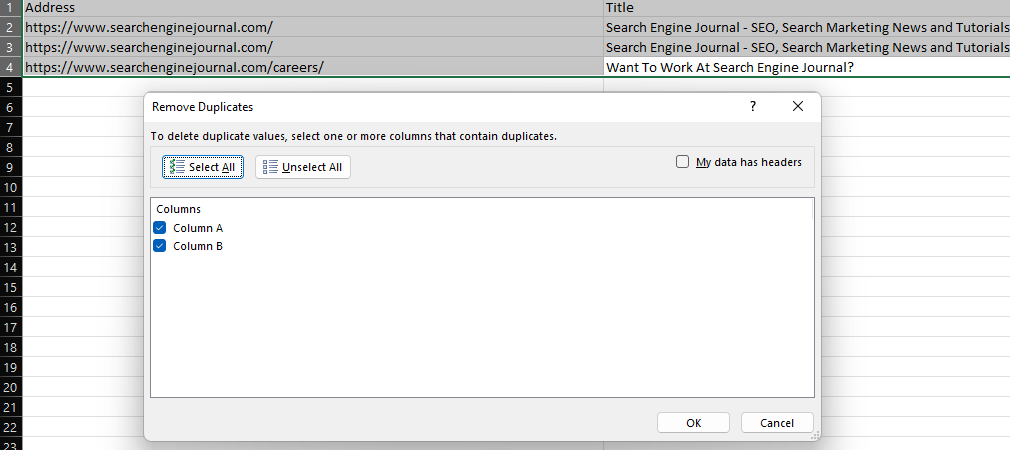
Otra característica fundamental de todos y cada uno de los días, la función «artículo a columnas» se puede emplear para dividir una cadena de artículo en función de un delimitador, como una barra inclinada, una coma o un espacio en blanco.
Por poner un ejemplo, dividir una dirección de Internet en su dominio y subcarpetas particulares.
-
Atrapa de pantalla de Microsoft Excel, noviembre de 2022
Tratándose de un marco de datos, tenemos la posibilidad de emplear la función str.split, que crea una lista para cada entrada en una matriz. Esto se puede transformar en múltiples columnas configurando el factor de extensión en True:
df['URL'].str.split(pat="/", expand=True)
-
 Atrapa de pantalla de VS Code, noviembre de 2022
Atrapa de pantalla de VS Code, noviembre de 2022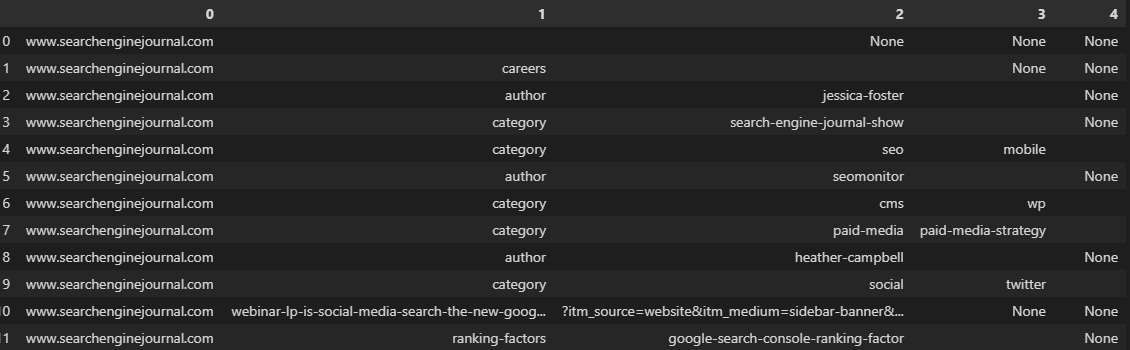
Como tiende a ser la situacion, las direcciones dirección de Internet en la imagen de arriba se dividieron en columnas inconsistentes por el hecho de que no detallan exactamente la misma proporción de carpetitas.
Esto puede complicar las cosas en el momento en que deseamos almacenar nuestros apuntes en un marco de datos que existe.
Detallar el factor n limita el número de particiones, permitiéndonos hacer un cierto número de columnas:
df[['Domain', 'Folder1', 'Folder2', 'Folder3']] = df['URL'].str.split(pat="/", expand=True, n=3)
Otra alternativa es utilizar pop para remover la columna del marco de datos, efectuar la división y después regresar a agregarla con la función de combinación:
df = df.join(df.pop('Split').str.split(pat="/", expand=True))
Duplicar la dirección de Internet en una exclusiva columna antes de dividirla nos deja sostener la dirección de Internet completa. Entonces tenemos la posibilidad de cambiar el nombre de las novedosas columnas: 🐆
df['Split'] = df['URL']
df = df.join(df.pop('Split').str.split(pat="/", expand=True))
df.rename(columns = , inplace=True)
-
 Atrapa de pantalla de VS Code, noviembre de 2022
Atrapa de pantalla de VS Code, noviembre de 2022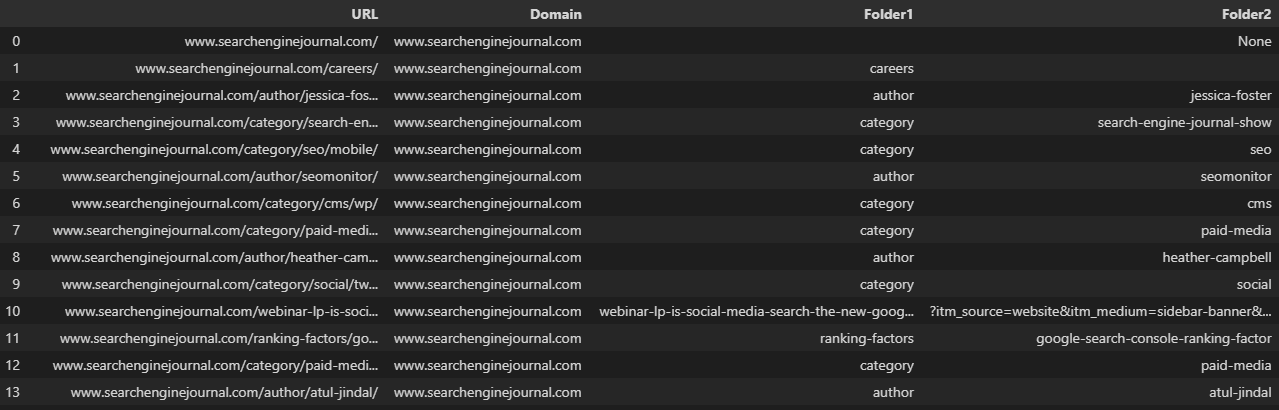
concatenar
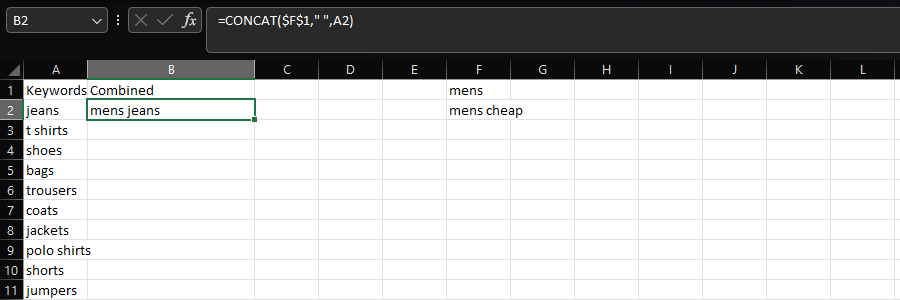
La función CONCAT deja a los individuos conjuntar múltiples cadenas de artículo, como en el momento en que se crea una lista de keywords añadiendo distintas modificadores.
En un caso así, añadimos «hombres» y espacios en blanco a la lista de géneros de artículos de la columna A:
=CONCAT($F$1," ",A2)

- Atrapa de pantalla de Microsoft Excel, noviembre de 2022
Suponiendo que nos encontramos intentando con cadenas, se puede poder lo mismo en Python utilizando el operador aritmético:
df['Combined] = 'mens' + ' ' + df['Keyword']
O especifique múltiples columnas de datos:
df['Combined'] = df['Subdomain'] + df['URL']
-
 Atrapa de pantalla de VS Code, noviembre de 2022
Atrapa de pantalla de VS Code, noviembre de 2022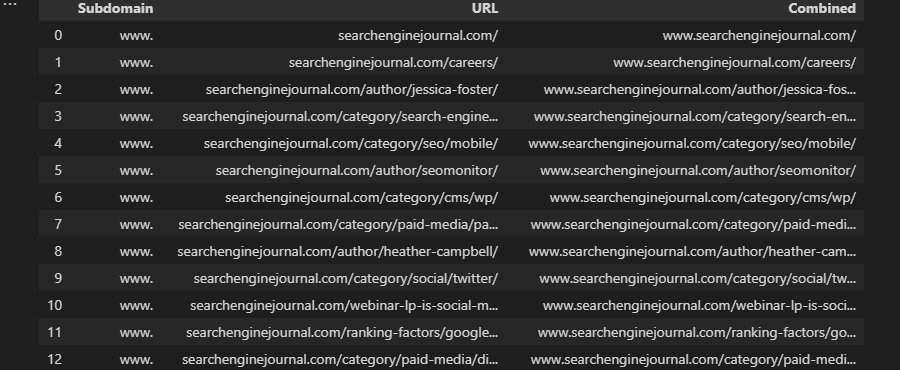
Pandas tiene una función concat dedicada, pero o sea mucho más útil en el momento en que se procura conjuntar múltiples marcos de datos con exactamente las mismas columnas.
Por servirnos de un ejemplo, si tuviésemos múltiples exportaciones de nuestra herramienta de análisis de links preferida:
df = pd.read_csv('data.csv')
df2 = pd.read_csv('data2.csv')
df3 = pd.read_csv('data3.csv')
dflist = [df, df2, df3]
df = pd.concat(dflist, ignore_index=True)
BUSCAR/ENCONTRAR
Las fórmulas SEARCH y FIND dan una manera de detectar una subcadena en una cadena de artículo.
Estos comandos normalmente se mezclan con ESNÚMERO para hacer una columna booleana que asiste para filtrar un grupo de datos, lo que puede ser increíblemente útil al efectuar tareas como investigar ficheros de registro, como se enseña en esta guía. Por poner un ejemplo:
=ISNUMBER(SEARCH("searchthis",A2)
-
 Atrapa de pantalla de Microsoft Excel, noviembre de 2022
Atrapa de pantalla de Microsoft Excel, noviembre de 2022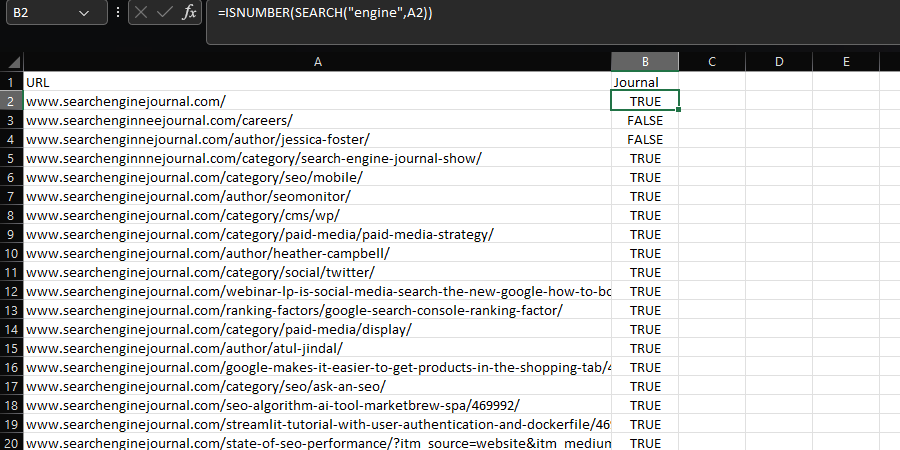
La diferencia entre SEARCH y FIND es que find distingue entre mayúsculas y minúsculas.
La función semejante de pandas, str.contains, distingue entre mayúsculas y minúsculas predeterminado:
df['Journal'] = df['URL'].str.contains('engine', na=False)
La distinción entre mayúsculas y minúsculas se puede activar configurando el factor de mayúsculas y minúsculas en Falso:
df['Journal'] = df['URL'].str.contains('engine', case=False, na=False)
En los dos niveles, integrar na=False evitará que se devuelvan valores nulos en la columna booleana.
Una enorme virtud de emplear pandas aquí es que, en contraste a Excel, las expresiones regulares son compatibles de manera nativa con esta característica, como en Hojas de cálculo de Google plus mediante REGEXMATCH.
Concatene múltiples subcadenas empleando el carácter de barra vertical, asimismo popular como el operador OR:
df['Journal'] = df['URL'].str.contains('engine|search', na=False)
Localizar y sustituir
La función Buscar y sustituir de Excel da una forma simple de sustituir individualmente o en masa una subcadena por otra.
-
 Atrapa de pantalla de Microsoft Excel, noviembre de 2022
Atrapa de pantalla de Microsoft Excel, noviembre de 2022
Al procesar datos para SEO, lo mucho más posible es que seleccionemos una columna completa y «Sustituir todo».
La fórmula SUSTITUIR da aquí otra alternativa y es útil si no quiere sobrescribir la columna que existe.
Por poner un ejemplo, tenemos la posibilidad de cambiar el protocolo de una dirección de Internet de HTTP a HTTPS o hacerla desaparecer reemplazándola por nada.
En el momento en que estamos trabajando con marcos de datos en Python, tenemos la posibilidad de emplear str.replace:
df['URL'] = df['URL'].str.replace('http://', 'https://')
O:
df['URL'] = df['URL'].str.replace('http://', '') # replace with nothing
De nuevo, en contraste a Excel, se tienen la posibilidad de utilizar expresiones regulares, como con REGEXREPLACE en Google plus Sheets:
df['URL'] = df['URL'].str.replace('http://|https://', '')
De forma alternativa, si quiere sustituir múltiples subcadenas con distintas valores, puede utilizar el procedimiento de remplazo de Python y proveer una lista.
Esto le impide encadenar múltiples funcionalidades str.replace:
df['URL'] = df['URL'].replace(['http://', ' https://'], ['https://www.', 'https://www.’], regex=True)
IZQUIERDA CENTRO DERECHA
La extracción de una subcadena en Excel necesita la utilización de las funcionalidades IZQUIERDA, CENTRO o DERECHA, en dependencia de dónde se halle la subcadena en una celda.
Afirmemos que deseamos obtener el dominio raíz y el subdominio de una dirección de Internet:
=MID(A2,FIND(":",A2,4)+3,FIND("/",A2,9)-FIND(":",A2,4)-3)
-
 Atrapa de pantalla de Microsoft Excel, noviembre de 2022
Atrapa de pantalla de Microsoft Excel, noviembre de 2022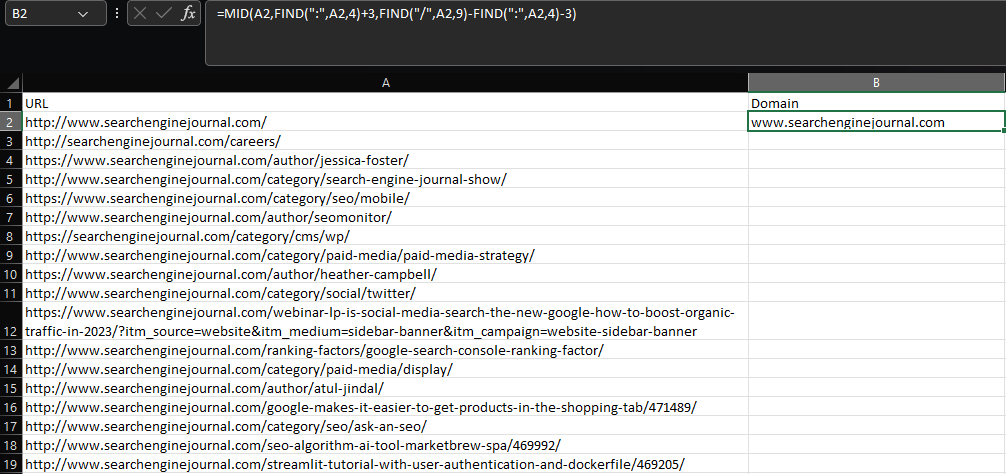
Utilizando una combinación de MID y múltiples funcionalidades FIND, esta fórmula es nada menos que fea, y esas cosas. se pone bastante peor para extracciones mucho más complicadas.
De nuevo, Google plus Sheets hace esto mejor que Excel por el hecho de que tiene REGEXEXTRACT.
Qué pena que en el momento en que lo alimentas con conjuntos de datos mucho más enormes, se funde mucho más veloz que un Babybel en un radiador ardiente.
Por fortuna, Pandas da str.extract, que marcha de forma afín:
df['Domain'] = df['URL'].str.extract('.*\://?([^/]+)')
-
 Atrapa de pantalla de VS Code, noviembre de 2022
Atrapa de pantalla de VS Code, noviembre de 2022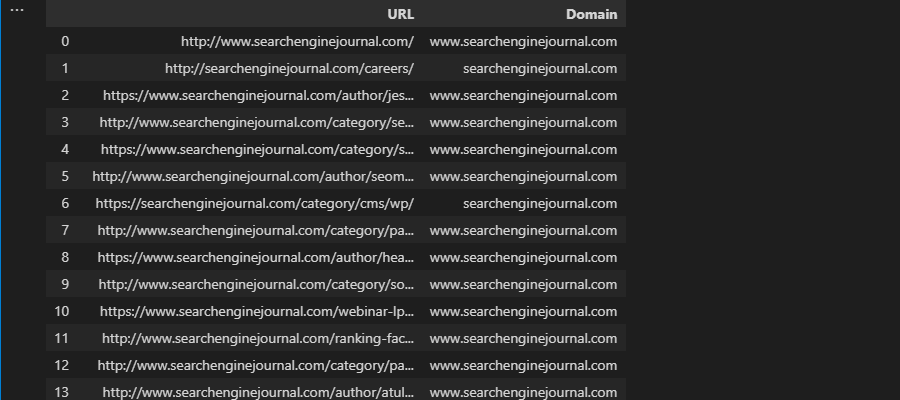
Mezcle con fillna para eludir valores nulos, como lo haría en Excel con IFERROR:
df['Domain'] = df['URL'].str.extract('.*\://?([^/]+)').fillna('-')
Uno mismo
Las afirmaciones IF le dejan devolver distintas valores en dependencia de si se cumple o no una condición.
Para ilustrar, pongamos que quiere hacer una etiqueta para las keywords que se clasifican en las tres primeras situaciones.
-
 Atrapa de pantalla de Microsoft Excel, noviembre de 2022
Atrapa de pantalla de Microsoft Excel, noviembre de 2022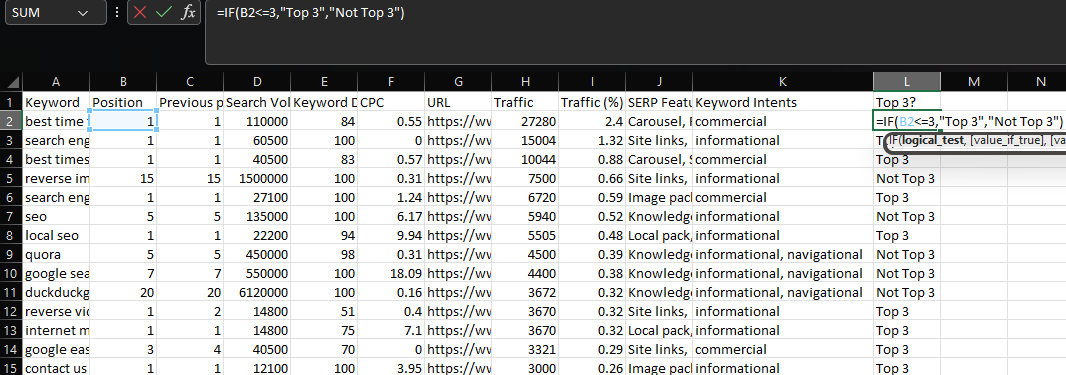
En vez de emplear pandas en un caso así, tenemos la posibilidad de confiar en NumPy y la función where (no olvide importar NumPy si aún no lo hizo):
df['Top 3'] = np.where(df['Position'] <= 3, 'Top 3', 'Not Top 3')
Se tienen la posibilidad de utilizar múltiples condiciones para exactamente la misma evaluación empleando los operadores AND/OR y encerrando los criterios particulares entre paréntesis:
df['Top 3'] = np.where((df['Position'] <= 3) & (df['Position'] != 0), 'Top 3', 'Not Top 3')
En lo previo, devolvemos "Top 3" para todas y cada una de las keywords que se clasifican en tres o menos, excluyendo las keywords que se clasifican en cero.
extensión ifs
En ocasiones, en vez de concretar múltiples condiciones para exactamente la misma evaluación, posiblemente quiera múltiples condiciones que devuelvan valores distintas.
En un caso así, la mejor solución es usar IFS:
=IFS(B2<=3,"Top 3",B2<=10,"Top 10",B2<=20,"Top 20")
-
 Atrapa de pantalla de Microsoft Excel, noviembre de 2022
Atrapa de pantalla de Microsoft Excel, noviembre de 2022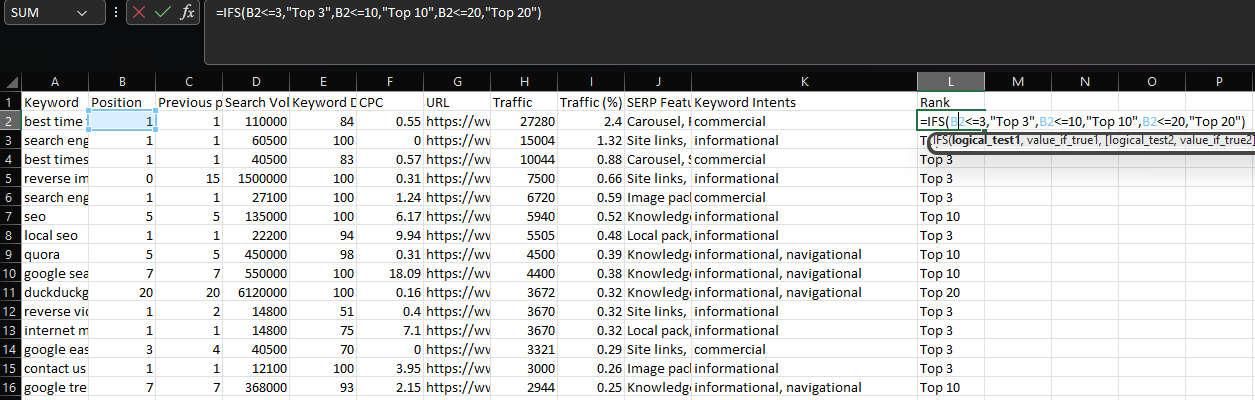
Nuevamente, NumPy nos ofrece la mejor solución en el momento de trabajar con tramas de datos, mediante la función de selección.
Con select, tenemos la posibilidad de hacer una lista de condiciones, opciones y un valor opcional para en el momento en que todas y cada una de las condiciones son falsas:
conditions = [df['Position'] <= 3, df['Position'] <= 10, df['Position'] <=20] choices = ['Top 3', 'Top 10', 'Top 20'] df['Rank'] = np.select(conditions, choices, 'Not Top 20')
Además, puede haber múltiples condiciones para cada una de las clasificaciones.
Supongamos que estamos trabajando con un minorista de comercio electrónico con páginas de listado de productos (PLP) y páginas de visualización de productos (PDP) y queremos etiquetar el tipo de páginas de marca que se clasifican entre los 10 primeros resultados.
La solución más simple aquí es buscar patrones de URL específicos, como una subcarpeta o extensión, pero ¿qué pasa si los competidores tienen patrones similares?
En este escenario, podríamos hacer algo como esto:
conditions = [(df['URL'].str.contains('/category/')) & (df['Brand Rank'] > 0),
(df['URL'].str.contains('/product/')) & (df['Brand Rank'] > 0),
(~df['URL'].str.contains('/product/')) & (~df['URL'].str.contains('/category/')) & (df['Brand Rank'] > 0)]
choices = ['PLP', 'PDP', 'Other']
df['Brand Page Type'] = np.select(conditions, choices, None)
Arriba, utilizamos str.contains para valorar si una dirección de Internet en el top 10 coincide o no con nuestro modelo de marca, entonces utilizamos la columna "Top de la marca" para descartar cualquier rivalidad.
En este caso de ejemplo, la tilde (~) señala una coincidencia negativa. En otras expresiones, deseamos que cada dirección de Internet de marca que no coincida con el patrón "PDP" o "PLP" coincida con los criterios de "Otro".
Al final, Ninguno está incluido por el hecho de que deseamos que los desenlaces sin marca devuelvan un valor nulo.
-
 Atrapa de pantalla de VS Code, noviembre de 2022
Atrapa de pantalla de VS Code, noviembre de 2022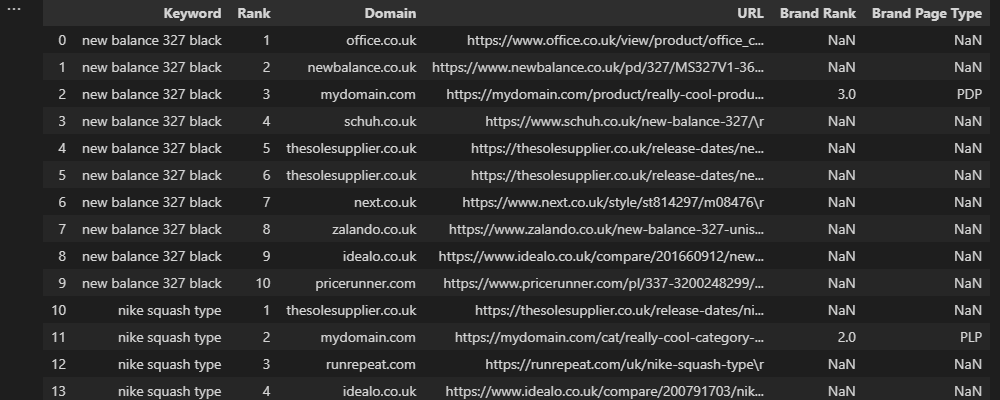
BUSCAR V
BUSCARV es una herramienta fundamental para fusionar 2 conjuntos de datos diferentes en una columna común.
En un caso así, añadiendo las dirección de Internet en la columna N a los datos de volumen de búsqueda, localización y keyword en las columnas AC, empleando la columna común "Keyword":
=VLOOKUP(A2,M:N,2,FALSE)
-
 Atrapa de pantalla de Microsoft Excel, noviembre de 2022
Atrapa de pantalla de Microsoft Excel, noviembre de 2022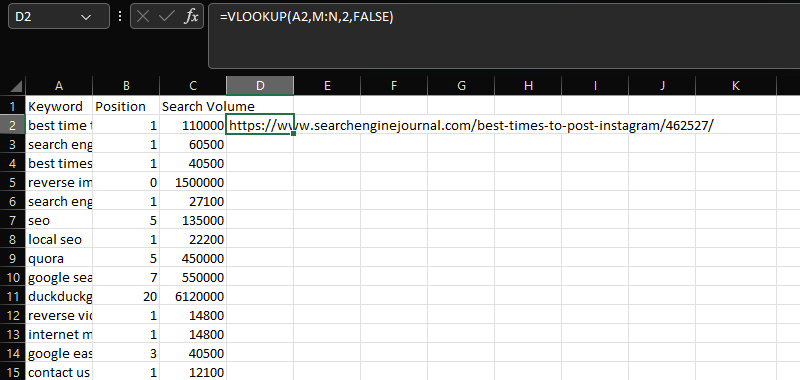
Para llevar a cabo algo afín con los pandas, tenemos la posibilidad de emplear go.
Al replicar la utilidad de una unión SQL, la fusión es una función impresionantemente vigorosa que acepta una pluralidad de géneros de unión distintas.
Para nuestros propósitos, deseamos emplear una combinación izquierda, que sostendrá nuestro primer marco de datos y solo unirá los valores coincidentes del segundo marco de datos:
mergeddf = df.merge(df2, how='left', on='Keyword')
Un beneficio agregada de efectuar una unión sobre BUSCARV es que no requiere comunicar los datos en la primera columna del segundo grupo de datos, como con el nuevo BUSCARX.
Asimismo conseguirá múltiples filas de datos en vez de la primera coincidencia en los desenlaces.
Un inconveniente común al emplear la función es la duplicación de columnas no deseada. Esto pasa en el momento en que hay múltiples columnas compartidas, pero procura emparejarlas empleando una.
Para eludir esto y prosperar la precisión de sus coincidencias, puede concretar una lista de columnas:
mergeddf = df.merge(df2, how='left', on=['Keyword', 'Search Volume'])
En ciertos niveles, posiblemente quiera integrar activamente estas columnas. Por poner un ejemplo, al procurar fusionar múltiples reportes de clasificación por mes:
mergeddf = df.merge(df2, on='Keyword', how='left', suffixes=('', '_october'))\
.merge(df3, on='Keyword', how='left', suffixes=('', '_september'))
El fragmento de código previo efectúa 2 uniones para juntar tres marcos de datos con exactamente las mismas columnas, que son nuestras clasificaciones para noviembre, octubre y septiembre.
Al etiquetar los meses en los factores de sufijo, conseguimos un marco de datos considerablemente más limpio que exhibe precisamente el mes, en contraste a los valores por defecto de _x y _y que se ven en el ejemplo previo.
-
 Atrapa de pantalla de VS Code, noviembre de 2022
Atrapa de pantalla de VS Code, noviembre de 2022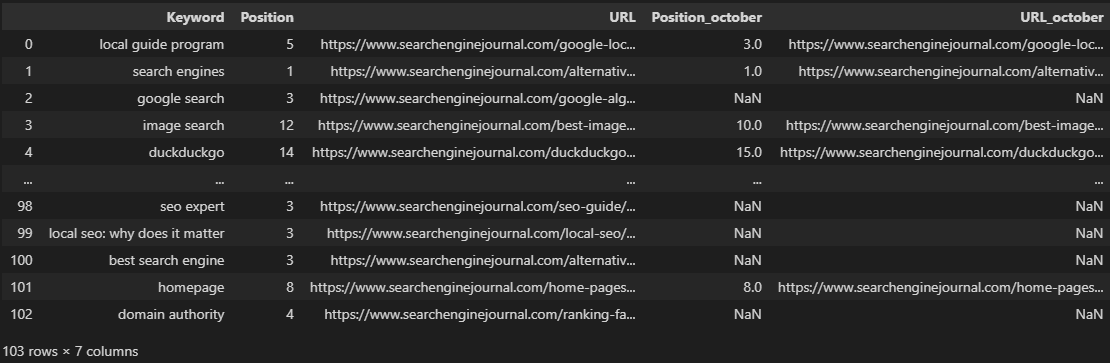
CONTAR.SI/SUMAR.SI/PROMEDIO.SI
En Excel, si quiere efectuar una función estadística fundamentada en una condición, puede emplear CONTAR.SI, SUMAR.SI o PROMEDIO.SI.
En la mayoría de los casos, COUNTIF se utiliza para saber cuántas ocasiones hace aparición una cadena cierta en un grupo de datos, como una dirección de Internet.
Tenemos la posibilidad de poder esto declarando la columna "dirección de Internet" como un rango, entonces la dirección de Internet de solo una celda como método:
=COUNTIF(D:D,D2)
-
 Atrapa de pantalla de Microsoft Excel, noviembre de 2022
Atrapa de pantalla de Microsoft Excel, noviembre de 2022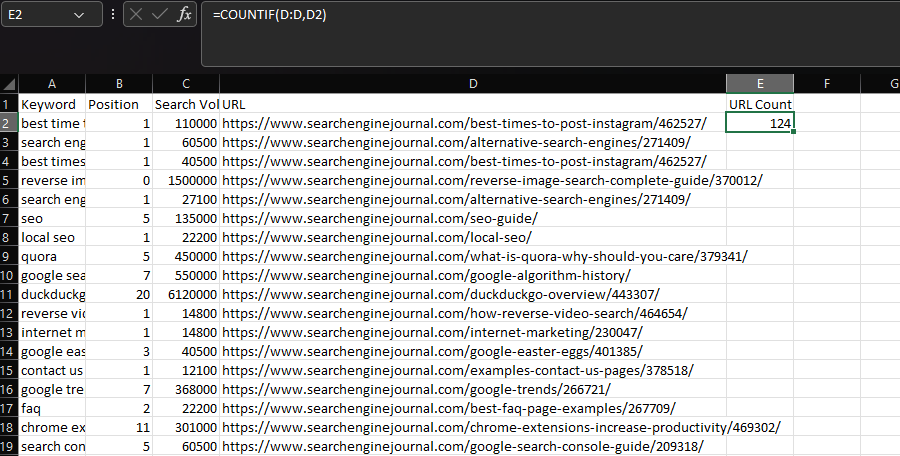
En Pandas, tenemos la posibilidad de conseguir exactamente el mismo resultado utilizando la función groupby:
df.groupby('dirección de Internet')['URL'].count()
-
Atrapa de pantalla de VS Code, noviembre de 2022
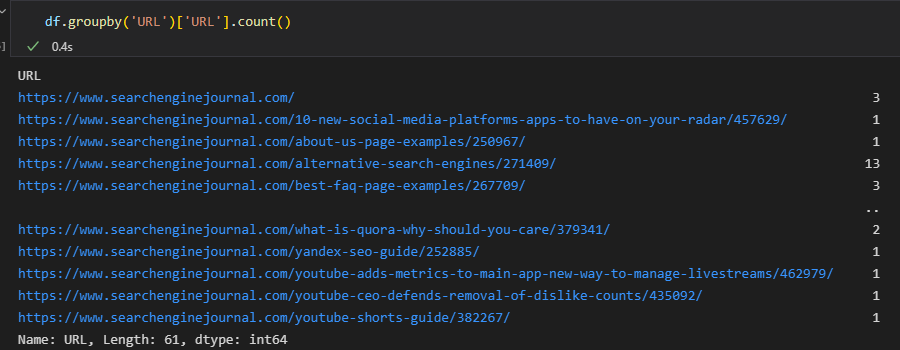
Aquí, la columna declarada entre paréntesis señala los conjuntos particulares, y la columna listada entre corchetes es donde se efectúa la agregación (esto es, el recuento).
No obstante, el resultado que conseguimos no es idóneo para esta situación de empleo pues afianza los datos.
En la mayoría de los casos, en el momento en que utilizamos Excel, tendríamos la proporción de dirección de Internet on line en nuestro grupo de datos. Entonces tenemos la posibilidad de emplearlo para filtrar las dirección de Internet más habituales enumeradas.
Para llevar a cabo esto, use transform y almacene el resultado en una columna:
df['URL Count'] = df.groupby('dirección de Internet')['URL'].transform('count')
-
 Atrapa de pantalla de VS Code, noviembre de 2022
Atrapa de pantalla de VS Code, noviembre de 2022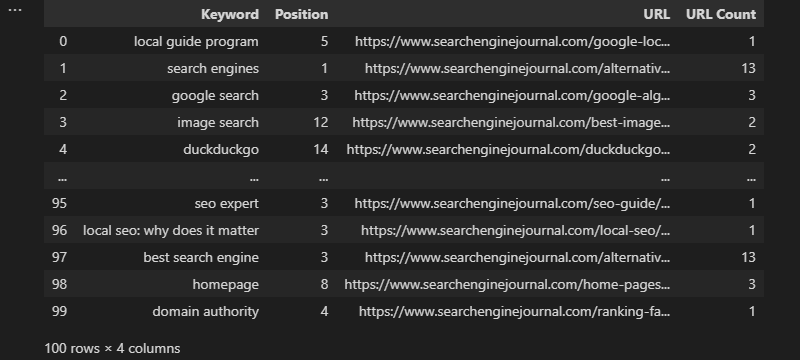
Asimismo puede utilizar funcionalidades adaptadas a conjuntos de datos a través de una función lambda (anónima):
df['Google Count'] = df.groupby(['URL'])['URL'].transform(lambda x: x[x.str.contains('google')].count())
En nuestros ejemplos hasta la actualidad, hemos utilizado exactamente la misma columna para nuestra agrupación y agregación, pero no es requisito. Afín a COUNTIFS/SUM.IF/AVERAGE.IFS en Excel, puede agrupar empleando una columna y después utilizar nuestra función estadística a otra.
Volviendo al ejemplo previo de la página de desenlaces del motor de búsqueda (SERP), posiblemente deseemos contar todos y cada uno de los PDP clasificados por keywords y devolver ese recuento adjuntado con nuestros apuntes que ya están:
df['PDP Count'] = df.groupby(['Keyword'])['URL'].transform(lambda x: x[x.str.contains('/product/|/prd/|/pd/')].count())
-
 Atrapa de pantalla de VS Code, noviembre de 2022
Atrapa de pantalla de VS Code, noviembre de 2022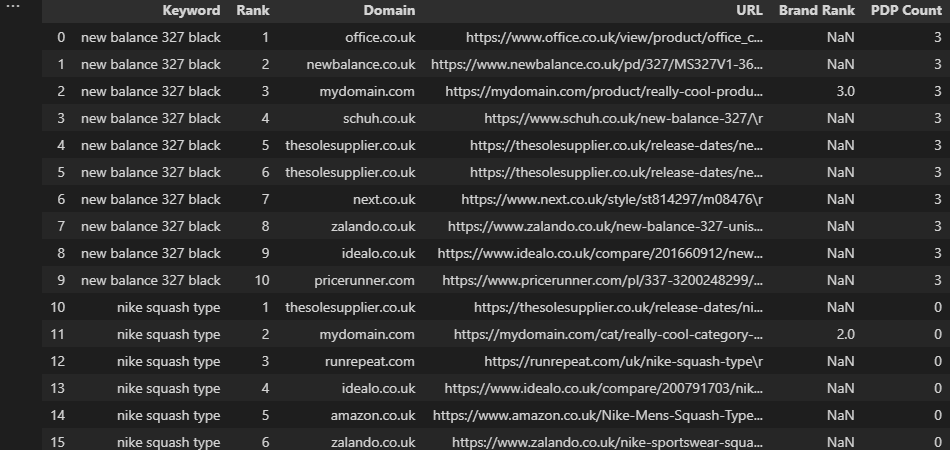
Que, en el lenguaje de Excel, se vería de esta forma:
=SUM(COUNTIFS(A:A,[@Keyword],D:D,))
Tablas dinamicas
Finalmente, pero no menos esencial, es hora de charlar de las tablas activas.
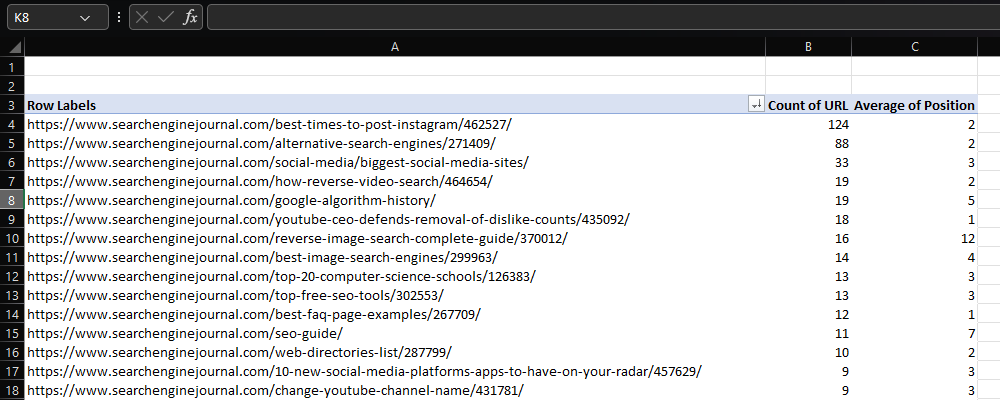
En Excel, una tabla activa es probablemente nuestro primer puerto de escala si deseamos sintetizar un enorme grupo de datos.
Por poner un ejemplo, en el momento en que estamos trabajando con datos de clasificación, posiblemente deseamos detectar qué dirección de Internet se muestran con mucho más continuidad y su situación promedio en la clasificación.
-
Atrapa de pantalla de Microsoft Excel, noviembre de 2022
De nuevo, pandas tiene sus tablas activas equivalentes, pero si todo cuanto quiere es contar los valores únicos en una columna, puede conseguirlo empleando la función value_counts:
count = df['URL'].value_counts()
Emplear groupby asimismo es una alternativa.
Previamente en el producto, llevar a cabo un groupby que agregara nuestros apuntes no era lo que deseábamos, pero es precisamente lo que requerimos aquí:
grouped = df.groupby('dirección de Internet').agg(
url_frequency=('Keyword', 'count'),
avg_position=('Position', 'orinan'),
)
grouped.reset_index(inplace=True)
-
 Atrapa de pantalla de VS Code, noviembre de 2022
Atrapa de pantalla de VS Code, noviembre de 2022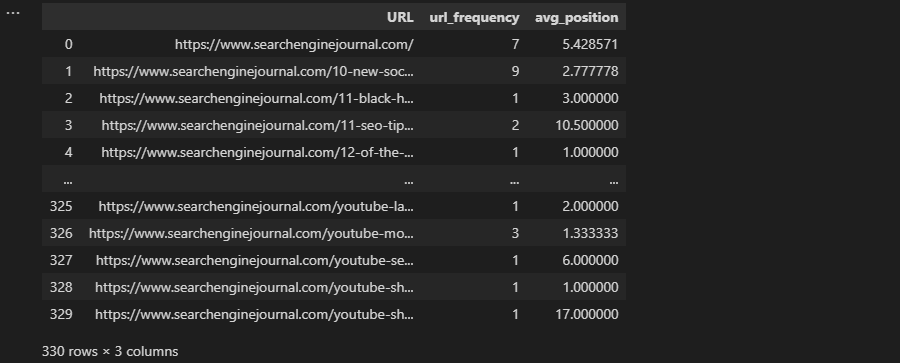
En el ejemplo previo, se aplicaron 2 funcionalidades agregadas, pero esto asimismo podría alcanzar de forma fácil 13 tipos distintas Están libres.
Hay, naturalmente, instantes en los que deseamos utilizar la tabla activa, como en el momento en que hacemos operaciones multidimensionales.
Para ilustrar lo que esto quiere decir, reutilicemos las agrupaciones de clasificación que creamos empleando afirmaciones condicionales y también procuremos ver cuántas ocasiones se clasifica una dirección de Internet en todos y cada agrupación.
ranking_groupings = df.groupby(['URL', 'Grouping']).agg(
url_frequency=('Keyword', 'count'),
)
-
 Atrapa de pantalla de VS Code, noviembre de 2022
Atrapa de pantalla de VS Code, noviembre de 2022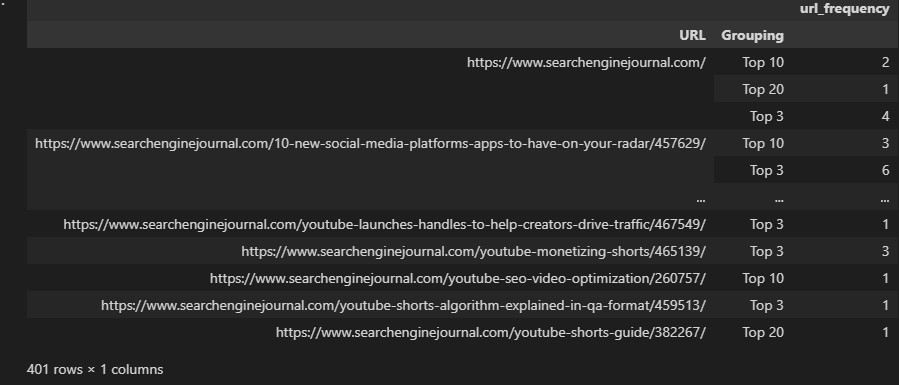
Este no es el más destacable formato para utilizar por el hecho de que se hicieron múltiples líneas para cada dirección de Internet.
En su rincón, tenemos la posibilidad de emplear la tabla activa, que mostrará los datos en distintas columnas:
pivot = pd.pivot_table(df, index=['URL'], columns=['Grouping'], aggfunc="size", fill_value=0, )
-
 Atrapa de pantalla de VS Code, noviembre de 2022
Atrapa de pantalla de VS Code, noviembre de 2022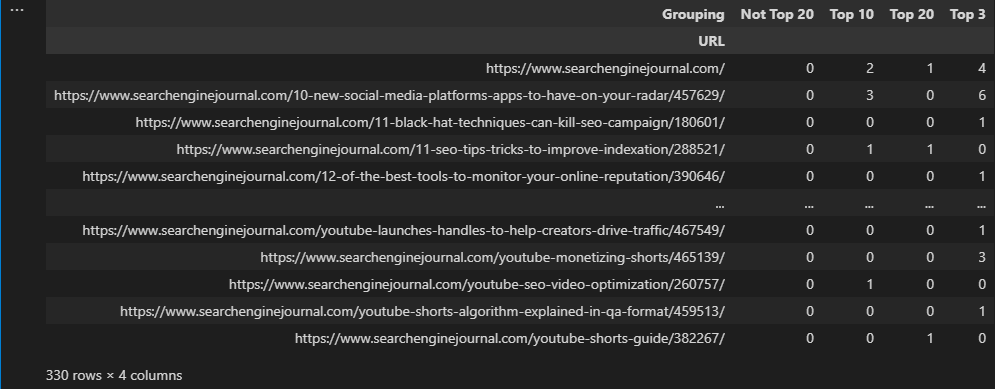
Pensamientos finales
Así sea que esté intentando encontrar inspiración para empezar a estudiar Python o que lo esté empleando en sus flujos de trabajo de SEO, quisiera que los ejemplos precedentes lo asistan en su sendero.
Como se prometió, puede hallar un cuaderno de Google plus Colab con todos y cada uno de los extractos de código Aquí.
Verdaderamente solo hemos rasguñado la área de lo que es viable, pero entender los conceptos básicos del análisis de datos de Python le va a dar una base sólida sobre la que crear.
Otros elementos:
Imagen señalada: mapo_japan/Shutterstock
Fuente: searchenginejournal
Hashtags: #Funcionalidades #fundamentales #para #análisis #datos #SEO
Comentarios recientes