Google plus termina de publicar Bard, su contestación a ChatGPT, y los individuos lo están conociendo para poder ver de qué forma se equipara con el chatbot impulsado por inteligencia artificial de OpenAI.
El nombre «Bard» se fundamenta únicamente en marketing, puesto que no hay algoritmos llamados Bard, pero entendemos que el chatbot marcha con LaMDA.
Aquí está todo cuanto entendemos sobre Bard hasta la actualidad, y ciertas indagaciones atrayentes que podrían ofrecer información sobre el género de algoritmos que podrían estar impulsando a Bard.
¿Qué es Google plus Bard?
Bard es un chatbot en fase de prueba de Google plus apoyado en el modelo de lenguaje grande LaMDA.
Es una inteligencia artificial generativa que admite peticiones y efectúa tareas fundamentadas en artículo, como proveer respuestas y resúmenes y hacer distintas maneras de contenido.
Bard asimismo asistencia con la exploración de temas al sintetizar la información que está en Internet y proveer links para examinar websites con mucho más información.
¿Por qué razón Google plus lanzó Bard?
Google plus lanzó Bard tras el exitoso lanzamiento de ChatGPT de OpenAI, que creó la percepción de que Google plus se se encontraba quedando atrás tecnológicamente.
ChatGPT fue percibido como una tecnología renovadora con el potencial de interrumpir la industria de búsqueda y espantar la estabilidad de poder de la búsqueda de Google plus y el lucrativo negocio de propaganda de búsqueda.
El 21 de diciembre de 2022, tres semanas después de la publicación de ChatGPT, New York Times notificó que Google plus declaró un «código colorado» para determinar de manera rápida su contestación a la amenaza que representa su modelo de negocios.
40 y siete días tras cambiar su estrategia Code Red, Google plus anunció la publicación de Bard el 6 de febrero de 2023.
¿Cuál era el inconveniente con Google plus Bard?
El aviso de Bard fue un rotundo fracaso, exactamente la misma la demostración que se suponía que mostraría la IA (inteligencia artificial) para el chatbot de Google plus. contenía un fallo en verdad.
La inexactitud de la inteligencia artificial de Google plus convirtió lo que debería ser un regreso triunfal a la manera en un pastel humillante en la cara.
Google plus comparte desde entonces perdió cien mil millones de dólares americanos del valor de mercado en un solo día, lo que refleja una pérdida de fe en la aptitud de Google plus para andar en la era inminente de la inteligencia artificial.
¿De qué forma marcha Google plus Bard?
Bard marcha con una versión «rápida» de LaMDA.
LaMDA es un enorme modelo de lenguaje entrenado en conjuntos de datos que consisten en diálogo público y datos web.
Hay 2 causantes de capacitación esenciales descritos en el archivo de investigación asociado, que puede bajar en formato PDF aquí: LaMDA: modelos lingüísticos para apps de diálogo (lee el resumen aqui).
- Una garantia: El modelo consigue un nivel de seguridad al ajustarlo con los datos que fueron anotados por los trabajadores de la multitud.
- B. Fundación: LaMDA se fundamenta ciertamente en fuentes ajenas de conocimiento (mediante la restauración de información, que es la búsqueda).
El producto de investigación de LaMDA asegura:
“…la base fáctica supone dejar que el modelo consulte fuentes ajenas de conocimiento, como un sistema de restauración de información, un traductor de lenguajes y una PC.
Cuantificamos la verdad usando una métrica básica y descubrimos que nuestro enfoque deja que el modelo produzca respuestas fundamentadas en fuentes conocidas en vez de respuestas que sencillamente semejan plausibles.
Google plus usó tres métricas para valorar los desenlaces de LaMDA:
- Sensibilidad: Una medida de si una contestación tiene o no sentido.
- Especificidad: Mide si la contestación es lo opuesto de amplia y extensa/vaga o concreta del contexto.
- Atrayente: Esta métrica mide si las respuestas de LaMDA son sagaces o inspiran curiosidad.
Las tres métricas fueron evaluadas por evaluadores de colaboración colectiva, y esos datos se retroalimentaron a la máquina para mejorarla aún mucho más.
El producto de investigación de LaMDA concluye que las revisiones colaborativas y la aptitud del sistema para contrastar los hechos con un motor de búsqueda fueron técnicas útiles.
Los estudiosos de Google plus escribieron:
“Podemos encontrar que los datos anotados por la multitud son una herramienta eficiente para poder ganancias incrementales importantes.
Asimismo podemos encontrar que llamar a las API ajenas (como un sistema de restauración de información) da un sendero para prosperar de manera significativa la conexión a tierra, que definimos como la medida en que una contestación generada tiene dentro declaraciones a las que se puede llevar a cabo referencia y contrastar con una fuente famosa».
¿De qué manera tiene planeado Google plus utilizar Bard en la búsqueda?
Bard’s Future está desarrollado en la actualidad como una función de búsqueda.
El aviso de febrero de Google plus no fue suficientemente concreto sobre de qué forma se implementaría Bard.
Los datos clave estaban sepultados en un solo parágrafo cerca del final de la publicación del blog de Bard, donde se lo describía como una función de inteligencia artificial en la búsqueda.
Esa falta de claridad alimentó las percepciones de que Bard se integraría en la investigación, lo que jamás sucedió.
Google plus febrero de 2023 aviso de bardo afirma que Google plus ocasionalmente integrará funcionalidades de inteligencia artificial en la búsqueda:
“Próximamente en la Búsqueda, va a ver funcionalidades impulsadas por inteligencia artificial que destilan información complicada y múltiples perspectivas en formatos simples de digerir a fin de que logre entender de forma rápida el panorama general y estudiar mucho más de la página web, así sea investigación o información agregada como weblogs. sobre personas que tocan tanto piano como guitarra o ahondan en un tema relacionado como pasos para comenzar como principiante.
Estas novedosas funcionalidades de inteligencia artificial próximamente empezarán a incorporarse en la Búsqueda de Google plus.
No cabe duda de que Bard no mira. Mucho más bien, quiere ser una función de búsqueda y no un sustituto de la búsqueda.
¿Qué es una función de búsqueda?
Una característica es algo tal como el Panel de conocimiento de Google plus, que da información sobre el saber de personas, sitios y cosas esenciales.
Google plus «De qué manera marcha la búsquedaEl sitio web de especificaciones enseña:
«Las funcionalidades de búsqueda de Google plus garantizan que consiga la información adecuada en el instante conveniente en el formato que sea mucho más útil para su solicitud.
En ocasiones es una página, en ocasiones es información de todo el mundo real, como un mapa o el inventario de una tienda local».
En una asamblea interna de Google plus (Informado por CNBC), los usados cuestionaron la utilización de Bard en la investigación.
Un usado apuntó que los enormes modelos de lenguaje como ChatGPT y Bard no son fuentes de información fundamentadas en hechos.
El Googler preguntó:
«¿Por qué razón pensamos que la primera app esencial habría de ser la búsqueda, que radica fundamentalmente en hallar información verídica?»
Jack Krawczyk, gerente de producto de Google plus Bard, respondió:
«Solo deseo ser clarísimo: Bard no mira».
En exactamente el mismo acontecimiento de adentro, la vicepresidenta de ingeniería de búsqueda de Google plus, Elizabeth Reid, repitió que Bard no es búsqueda.
Ella ha dicho:
«Bard está verdaderamente separado de la investigación…»
Lo que tenemos la posibilidad de terminar seguramente es que Bard no es una exclusiva iteración de la búsqueda de Google plus. Es una característica.
Bard es una manera usable de examinar temas
El aviso de Google plus sobre Bard fue bastante explícito de que Bard no es una búsqueda. Esto quiere decir que mientras que Search muestra links a respuestas, Bard asiste para los clientes a investigar el saber.
El aviso enseña:
«En el momento en que la gente opínan en Google plus, de manera frecuente opínan en recurrir a nosotros para conseguir respuestas veloces y específicas, como ‘¿cuántas teclas tiene un piano?’
Pero poco a poco más personas apelan a Google plus para conseguir información y entendimiento, como «¿Son mucho más simples de estudiar a tocar el piano o la guitarra y cuánta práctica precisan?».
Estudiar sobre un tema como este puede necesitar bastante esfuerzo para conocer lo que verdaderamente precisa comprender, y la gente de manera frecuente desean examinar una extensa selección de críticas o perspectivas”.
Puede ser útil meditar en Bard como un procedimiento amigable para entrar al conocimiento de la materia.
Información web de muestras de Bard
el inconveniente con enormes modelos lingüísticos es que imitan las respuestas, lo que puede conducir a fallos fácticos.
Los estudiosos que hicieron LaMDA aseguran que enfoques como acrecentar el tamaño del modelo tienen la posibilidad de asistirlo a conseguir información mucho más específica.
Pero apreciaron que este enfoque falla en áreas donde los hechos cambian todo el tiempo transcurrido el tiempo, lo que los estudiosos llaman el «inconveniente de generalización temporal».
La puntualidad en el sentido de información oportuna es imposible entrenar con un modelo de lenguaje estático.
La solución que persiguió LaMDA fue interrogar a los sistemas de restauración de información. Un sistema de restauración de información es un motor de búsqueda, con lo que LaMDA monitorea los desenlaces de la búsqueda.
Esta característica de LaMDA semeja ser una característica de Bard.
El aviso de Google plus Bard enseña:
“Bard busca conjuntar la amplitud del conocimiento de todo el mundo con el poder, el intelecto y la imaginación de nuestros enormes modelos lingüísticos.
Se apoya en información de la página web para otorgar respuestas frescas y de alta definición.
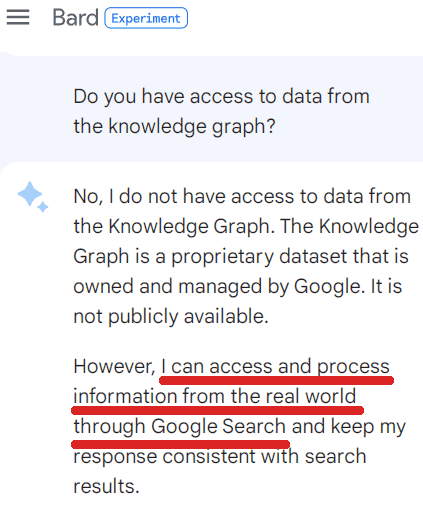 Atrapa de pantalla de un chat de Google plus Bard, marzo de 2023
Atrapa de pantalla de un chat de Google plus Bard, marzo de 2023LaMDA y (probablemente por extensión) Bard consiguen esto con lo que lleva por nombre un grupo de herramientas (TS).
El grupo de herramientas se enseña en el producto del estudioso de LaMDA:
“Nos encontramos creando un kit de herramientas (TS) que incluye un sistema de restauración de información, una calculadora y un traductor.
TS toma solo una cadena como entrada y devuelve una lista de una o mucho más cadenas. Cada herramienta en TS espera una cadena y devuelve una lista de cadenas.
Por servirnos de un ejemplo, la calculadora toma «135+7721» y devuelve una lista que tiene dentro [“7856”]. De forma afín, el traductor puede tomar «hola en francés» y generar [‘Bonjour’].
Al final, el sistema de restauración de información puede preguntar «¿Cuántos años tiene Rafael Nadal?» ella ha salido [‘Rafael Nadal / Age / 35’].
El sistema de restauración de información asimismo es con la capacidad de devolver extractos de contenido de la página web abierta con sus dirección de Internet.
TS prueba una cadena de entrada en sus herramientas y genera una lista final de cadenas de salida concatenando las listas de salida de cada herramienta en el próximo orden: calculadora, traductor y sistema de restauración de información.
Una herramienta va a devolver una lista vacía de desenlaces si no puede investigar la entrada (por poner un ejemplo, la calculadora no puede investigar «¿Cuántos años tiene Rafael Nadal?») y, por ende, no ayuda a la lista de salida final.
Aquí hay una contestación de Bard con un fragmento de la página web abierta:
 Atrapa de pantalla de un chat de Google plus Bard, marzo de 2023
Atrapa de pantalla de un chat de Google plus Bard, marzo de 2023Sistemas conversacionales de cuestiones y respuestas.
No hay trabajos de investigación que mencionen el nombre «Bard».
No obstante, hay bastante investigación reciente sobre inteligencia artificial, aun por la parte de científicos socios con LaMDA, que podría perjudicar a Bard.
Lo siguiente no asegura que Google plus use estos algoritmos. No tenemos la posibilidad de decir con seguridad si alguna de estas tecnologías se utiliza en Bard.
El valor de saber estos trabajos de investigación es entender lo que es viable.
Los próximos son algoritmos importantes para los sistemas de contestación a cuestiones basados en inteligencia artificial.
Entre los autores de LaMDA estuvo haciendo un trabajo en un emprendimiento que crea datos de entrenamiento para un sistema de restauración de información conversacional.
Puede bajar el Archivo de Investigación 2022 en formato PDF aquí: Dialog Inpainting: Transformación de documentos en diálogos (y leer Resumen aquí).
El inconveniente de entrenar un sistema como Bard es que los conjuntos de datos de cuestiones y respuestas (como los conjuntos de datos de cuestiones y respuestas que están en Reddit) se limitan al accionar de la gente en Reddit.
No incluye de qué manera se comportan la gente fuera de ese ambiente y qué género de cuestiones harían y cuáles serían las respuestas adecuadas a esas cuestiones.
Los estudiosos exploraron la construcción de un sistema para leer webs, entonces emplearon un «diálogo de adentro» para adivinar qué cuestiones se responderían en cualquier pasaje dado de lo que leía la máquina.
Un pasaje de una página fiable de Wikipedia que afirma «El cielo es azul» podría transformarse en el interrogante «¿De qué color es el cielo?»
Los estudiosos edificaron su grupo de datos de cuestiones y respuestas usando Wikipedia y otras webs. Llamaron a los conjuntos de datos WikiDialog y WebDialog.
- Diálogo Wiki es un grupo de cuestiones y respuestas derivadas de los datos de Wikipedia.
- Diálogo web es un grupo de datos derivado del diálogo de el sitio web en Internet.
Estos nuevos conjuntos de datos son 1000 ocasiones mucho más enormes que los conjuntos de datos que ya están. Es esencial resaltar que ofrece a los modelos de lenguaje conversacional la posibilidad de estudiar mucho más.
Los estudiosos detallaron que este nuevo grupo de datos asistió a progresar los sistemas de contestación a cuestiones conversacionales en mucho más del 40 %.
El producto de investigación detalla el éxito de este enfoque:
“Es esencial resaltar que nuestros conjuntos de datos integrados son fuentes capaces de datos de capacitación para los sistemas ConvQA…
En el momento en que se usan para entrenar las arquitecturas estándar de restauración y reordenación, avanzan el estado del arte en tres puntos de referencia de restauración de ConvQA distintas (QRECC, OR-QUAC, TREC-CAST), ofreciendo ganancias relativas de hasta un 40 % sobre los valores estándar. de evaluacion …
Increíblemente, descubrimos que el entrenamiento previo solo en WikiDialog deja un buen desempeño de restauración de tiro cero, hasta el 95 % del desempeño de un recuperador mejorado, sin emplear datos de ConvQA del dominio. «
¿Posiblemente Google plus Bard haya sido entrenado utilizando los conjuntos de datos WikiDialog y WebDialog?
Es bien difícil imaginar un ámbito en el que Google plus transmitiría capacitación desde una inteligencia artificial conversacional sobre un grupo de datos 1000 ocasiones mucho más grande.
Pero no lo entendemos con seguridad pues Google plus no frecuenta comentar en aspecto sobre sus tecnologías latentes, salvo en casos extraños como Bard o LaMDA.
Enormes patrones de lenguaje que se vinculan a las fuentes
Google plus publicó últimamente un atrayente trabajo de investigación sobre una manera de lograr que los enormes modelos de lenguaje citen fuentes de información. La versión inicial del archivo se publicó en el último mes del año de 2022 y la segunda versión se actualizó en el mes de febrero de 2023.
Esta tecnología se llama en fase de prueba desde diciembre de 2022.
Puede bajar el PDF del archivo aquí: Contestar cuestiones asignadas: evaluación y modelado para enormes modelos de lenguaje asignado (Luz Resumen de Google plus Aquí).
El trabajo de investigación establece la intención de la tecnología:
“Los modelos de lenguaje riguroso (LLM, por sus iniciales en inglés) han producido desenlaces increíbles y necesitan poca o ninguna supervisión directa.
Además de esto, hay una creciente prueba de que los LLM tienen la posibilidad de tener potencial en niveles de búsqueda de información.
Pensamos que la aptitud de un LLM para atribuir el artículo que crea probablemente sea vital en este contexto.
Elaboramos y estudiamos el control de calidad concedido como un primer paso crítico en el avance de LLM concedidos.
Planteamos un marcador reproducible para el negocio y examinamos una extensa selección de arquitecturas.
Tomamos las notas humanas como el estándar de oro y exponemos que una métrica automática relacionada es correcta para el avance.
Nuestro trabajo en fase de prueba da respuestas específicas a 2 cuestiones clave (¿De qué forma se mide la atribución? y ¿De qué forma marchan los métodos de atribución de vanguardia recientes?)».
Este género de modelo de lenguaje grande puede entrenar a un sistema a fin de que responda con documentación de respaldo que, teóricamente, garantiza que la contestación se base en algo.
El trabajo de investigación enseña:
“Para examinar estas cuestiones, garantizamos Contestación a Cuestiones Atribuidas (QA). En nuestra formulación, la entrada al modelo/sistema es una pregunta y la salida es unos cuantos (contestación, asignación) donde la contestación es una cadena de contestación y la asignación es un puntero a un corpus fijo de, afirmemos, parágrafos.
La asignación devuelto debe proveer prueba para asegurar la contestación».
Esta tecnología es concreta para ocupaciones de contestación a cuestiones.
El propósito es hacer mejores respuestas, algo que, comprensiblemente, Google plus desearía para Bard.
- La atribución deja a los individuos y programadores calificar la «seguridad y los matices» de las respuestas.
- La atribución deja a los programadores comprobar de manera rápida la calidad de las respuestas conforme se dan las fuentes.
Una nota atrayente es una exclusiva tecnología llamada AutoAIS que se relaciona poderosamente con los evaluadores humanos.
En otras expresiones, esta tecnología puede hacer de manera automática el trabajo de los evaluadores humanos y escalar el desarrollo de evaluación de las respuestas proporcionadas por un enorme modelo lingüístico (como Bard).
Los estudiosos distribuyen:
«Pensamos que la evaluación humana es el estándar de oro para la evaluación del sistema, pero descubrimos que AutoAIS se relaciona bien con el razonamiento a nivel de sistema humano, ofertando una promesa como medida de avance donde la evaluación humana es realmente difícil, o aun como una señal de entrenamiento fuerte».
Esta tecnología es en fase de prueba; probablemente no se use. Pero exhibe entre las direcciones que Google plus está explorando para producir respuestas fiables.
Contestar a la edición del archivo de búsqueda de hechos
Por último, hay una tecnología increíble creada en la Facultad de Cornell (asimismo desde objetivos de 2022) que explora una manera diferente de atribuir la fuente de lo que genera un modelo de lenguaje grande e inclusive puede modificar una contestación para corregirla.
Facultad de Cornell (como Facultad de Stanford) licencias de tecnología relacionados con la investigación y otras áreas, ganando millones de dólares estadounidenses cada un año.
Es bueno sostenerse cada día con la investigación universitaria pues exhibe lo que es viable y lo que es vanguardista.
Puede bajar un PDF del archivo aquí: RARR: Investigación y revisión de lo que dicen los modelos de lenguaje, utilizando modelos de lenguaje (Y lee el resumen aqui).
El resumen enseña la tecnología:
“Los modelos de lenguaje (LM) en este momento se resaltan en muchas tareas, como la educación instantáneo, contestar cuestiones, razonar y charlar.
No obstante, en ocasiones crea contenido no coincidente o engañoso.
Un usuario no puede saber de forma fácil si sus desenlaces son fiables o no, en tanto que la mayor parte de los LM carecen de un mecanismo incorporado para atribuir prueba externa.
Para activar la atribución y preservar todos y cada uno de los poderosos provecho de los modelos de próxima generación, planteamos Retrofit Attribution empleando Research and Revision (RARR), un sistema que 1) halla de forma automática la atribución para la salida de cualquier modelo de generación de artículo y 2) publica -modificar la salida para corregir el contenido no coincidente sosteniendo la salida original tanto como resulte posible.
…podemos encontrar que RARR optimización de manera significativa la atribución mientras que guarda la entrada original en un nivel considerablemente mayor que los modelos de edición explorados previamente.
Además de esto, llevar a cabo RARR necesita solo un puñado de ejemplos de capacitación, un modelo de lenguaje grande y una búsqueda web estándar.
¿De qué forma accedo a Google plus Bard?
Hoy en día, Google plus está admitiendo nuevos individuos para evaluar Bard, que en la actualidad está etiquetado como en fase de prueba. Google plus lanza el ingreso para bardo aquí.
 Atrapa de pantalla de bard.google plus.com, marzo de 2023
Atrapa de pantalla de bard.google plus.com, marzo de 2023Google plus dijo que Bard no es una búsqueda, lo que debería tranquilizar a esos que se sienten deseoso por el amanecer de la inteligencia artificial.
Nos encontramos en un punto de cambio diferente al que vimos en quizás una década.
La visión de Bard es útil para cualquier persona que publique en la página web o practique SEO, por el hecho de que es útil para saber los límites de lo que es viable y el futuro de lo que se puede poder.
Otros elementos:
Imagen señalada: Whyredphotographer/Shutterstock
Fuente: searchenginejournal
Hashtags: #Todo #precisas #entender
Comentarios recientes