La optimización de buscadores web, en su sentido mucho más básico, hablamos de solo una cosa: las arañas de los buscadores web rastrean y también indexan su ubicación.
Pero prácticamente todos los websites van a tener páginas que no quiere integrar en este escaneo.
Por servirnos de un ejemplo, ¿verdaderamente quiere que su política de intimidad o las páginas de búsqueda internas aparezcan en los desenlaces de Google plus?
En el más destacable de las situaciones, no hacen nada para regentar activamente el tráfico a su lugar y, en el peor caso, tienen la posibilidad de desviar el tráfico de sus páginas mucho más esenciales.
Por fortuna, Google plus deja a los administradores de páginas web decirles a los robots de los buscadores qué páginas y contenido seguir y qué ignorar. Hay múltiples maneras de realizar esto, la más habitual es emplear un fichero robots.txt o la metaetiqueta robots.
Disponemos una increíble y descriptiva explicación de las desventajas de robots.txt que terminantemente deberías leer.
Pero en concepto de prominente nivel, es un fichero de artículo fácil que está en la raíz de su ubicación y prosigue Protocolo de exclusión de robots (REP).
Robots.txt da a los rastreadores normas sobre el ubicación en su grupo, al paso que las metaetiquetas de robots tienen dentro normas para páginas concretas.
Ciertas etiquetas de metabot que puede utilizar tienen dentro índiceque le afirma a los buscadores que añadan la página a su índice; sin índicemencionarle que no indexe una página ni la integre en los resultados de la búsqueda; Proseguirque le señala a un motor de búsqueda que prosiga los links en una página; no prosigasdiciéndole que no prosiga los links y considerablemente más.
Tanto las etiquetas robots.txt como las misión robots son herramientas útiles para sostener en su caja de herramientas, pero hay otra forma de entrenar a los bots de los buscadores web a fin de que no indexen o no prosigan: X-Robots-Etiqueta.
¿Qué es X-Robots-Tag?
X-Robots-Tag es otra forma de supervisar de qué manera las arañas rastrean y también indexan sus webs. Como una parte de la contestación del encabezado HTTP a una dirección de Internet, controla la indexación de una página completa y elementos concretos en esa página.
Y al tiempo que emplear etiquetas de misión-robots es bastante simple, X-Robots-Tag es un tanto más difícil.
Pero, como es natural, esto expone el interrogante:
¿Cuándo debería utilizar X-Robots-Tag?
Obediente Google plus«Cualquier directiva que se logre utilizar en una metaetiqueta de robots asimismo se puede concretar como una etiqueta de X-Robots».
Más allá de que puede detallar ordenes de robots.txt en los encabezados de una contestación HTTP con la metaetiqueta de robots y la etiqueta X-Robots, existen algunas ocasiones en las que quiere emplear la etiqueta X-Robots: ámbas más habituales. ser en el momento en que:
- Quiere supervisar de qué manera se rastrean y también indexan sus ficheros que no son HTML.
- Quiere pasar ordenes en todo el lugar en vez de a nivel de página.
Por servirnos de un ejemplo, si quiere eludir que se escanee una imagen o vídeo concreto, el procedimiento de contestación HTTP lo realiza mucho más simple.
El encabezado X-Robots-Tag asimismo es útil por el hecho de que le deja conjuntar múltiples etiquetas en una contestación HTTP o emplear una lista de ordenes separadas por comas para detallar ordenes.
Quizás no quiera que una cierta página se almacene en caché y quiera que no esté libre tras una cierta fecha. Puede emplear una combinación de etiquetas «noarchive» y «unavailable_after» para señalar a los robots de los buscadores que prosigan estas normas.
En esencia, la fuerza de X-Robots-Tag es que es considerablemente más maleable que la metaetiqueta de robots.
El beneficio de emplear un X-Robots-Tag con las respuestas HTTP es que le deja emplear expresiones regulares para realizar ordenes de exploración no HTML, tal como utilizar factores en un nivel global mucho más extenso.
Para asistirlo a entender la diferencia entre estas ordenes, es útil catalogarlas por tipo. Esto es, ¿son ordenes de rastreador o ordenes de índice?
Aquí hay una práctica hoja de trucos:
| Ordenes de rastreadores | Ordenes de indexación |
| Robots.txt – utilice las ordenes de agente de usuario, permiso, rechazo y mapa del lugar para detallar dónde tienen la posibilidad de seguir los bots del motor de búsqueda en su ubicación y dónde no se les deja seguir. | Etiqueta Misión Robot – le deja concretar y eludir que los buscadores web hagan ver algunas páginas de un ubicación en los resultados de la búsqueda.
no continuar – le deja detallar links que no tienen que trasmitir autoridad o PageRank. Etiqueta X-Robots – Controla de qué manera se indexan las clases de ficheros concretados. |
¿Dónde pones la etiqueta de X-Robots?
Afirmemos que quiere denegar algunos géneros de ficheros. Un enfoque ideal sería añadir X-Robots-Tag a una configuración de Apache o un fichero .htaccess.
La etiqueta X-Robots se puede añadir a las respuestas HTTP de un lugar en una configuración de servidor Apache a través del fichero .htaccess.
Ejemplos y usos reales de la etiqueta X-Robots
Eso suena excelente teóricamente, pero ¿de qué manera es en el planeta real? Veremos.
Pongamos que no quiere que los buscadores web indexen los modelos de ficheros .pdf. Esta configuración en los servidores Apache se vería de esta forma:
Header equipo X-Robots-Tag "noindex, nofollow"
En Nginx, se vería de esta manera:
location ~* \.pdf$
En este momento, observemos un ámbito diferente. Imaginemos que deseamos utilizar X-Robots-Tag para denegar la indexación de ficheros de imagen como .jpg, .gif, .png, etcétera. Puede realizar esto con una etiqueta X-Robots que se vería de esta manera:
Header equipo X-Robots-Tag "noindex"
Tenga presente que entender de qué forma marchan estas ordenes y de qué manera se afectan entre sí es vital.
Por poner un ejemplo, ¿qué ocurre si tanto la etiqueta X-Robots como la etiqueta metarobots se sitúan en el momento en que los rastreadores se dan cuenta una dirección de Internet?
Si esa dirección de Internet está denegada por robots.txt, ciertas ordenes de indexación y publicación no se tienen la posibilidad de conocer y no se proseguirán.
Si se tienen que continuar las ordenes, las dirección de Internet que las poseen no se tienen la posibilidad de seguir.
Busque una etiqueta de X-Robots
Existen varios métodos que se tienen la posibilidad de usar para revisar si hay una etiqueta de X-Robots en el ubicación.
La manera mucho más fácil de revisarlo es disponer un extensión del navegador que le afirmará a X-Robots-Tag información sobre la dirección de Internet.
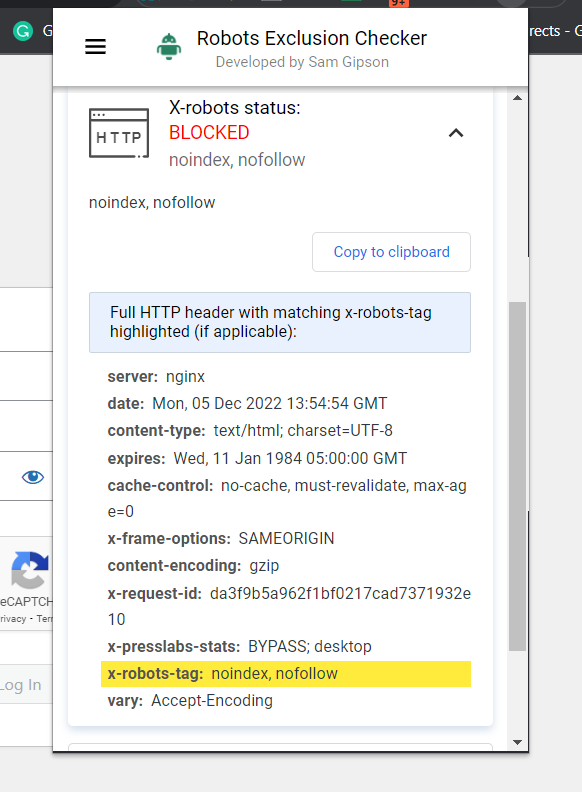 Atrapa de pantalla de Robots Exclusion Checker, diciembre de 2022
Atrapa de pantalla de Robots Exclusion Checker, diciembre de 2022Otro complemento que puede utilizar para saber si se está empleando una etiqueta X-Robots, por poner un ejemplo, es Complementos para programadores web.
Al clickear en el complemento en su navegador y andar a «Ver encabezados de contestación», puede ver los distintos encabezados HTTP empleados.

Otro procedimiento que se puede emplear para detectar inconvenientes en websites de millones de páginas es Screaming Frog.
Tras realizar un ubicación mediante Screaming Frog, puede proceder a la columna «X-Robots-Tag».
Esto le mostrará qué partes del ubicación utilizan la etiqueta, adjuntado con qué ordenes concretas.
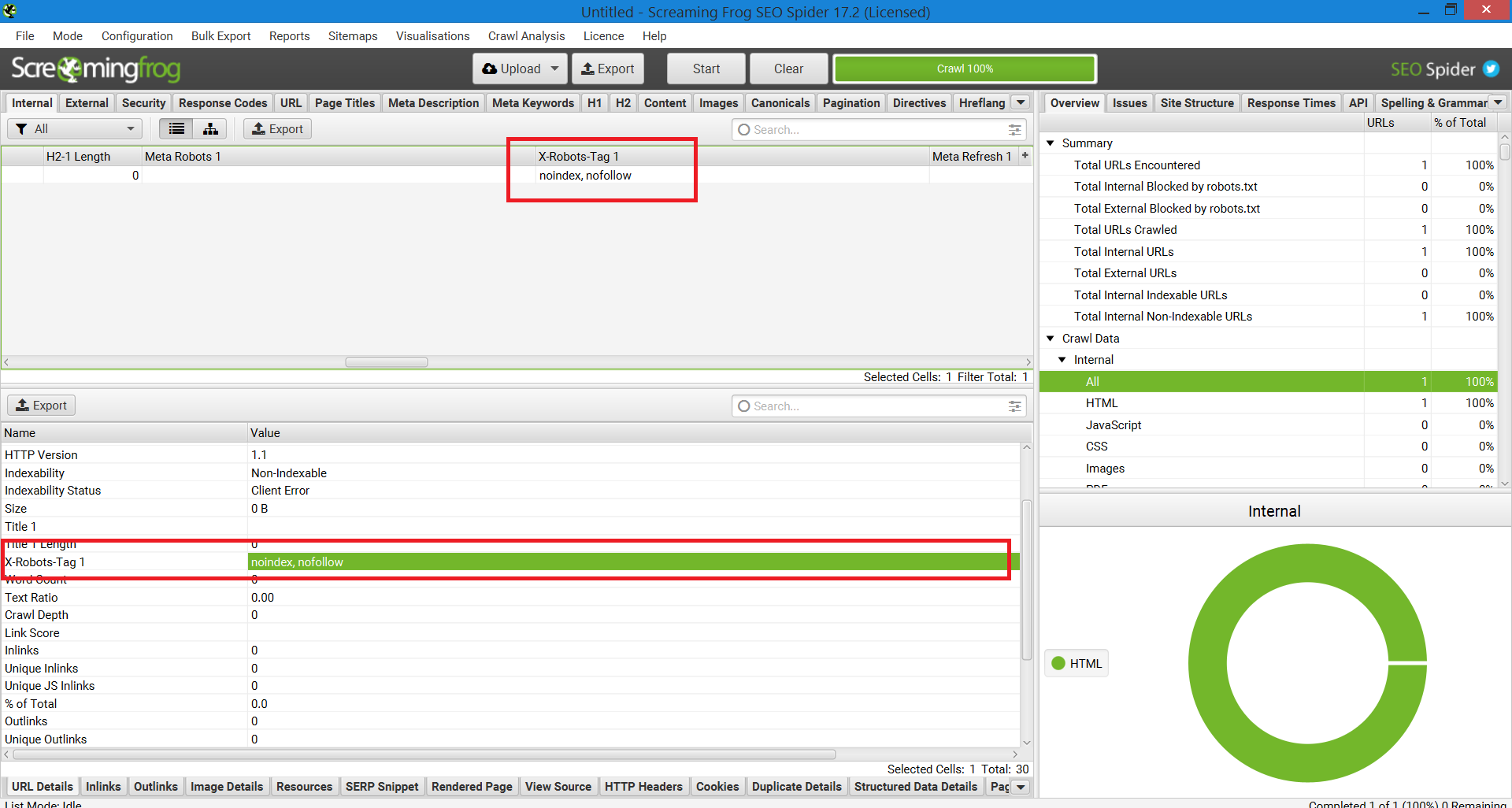 Atrapa de pantalla del informe Screaming Frog. X-Robot-Tag, diciembre de 2022
Atrapa de pantalla del informe Screaming Frog. X-Robot-Tag, diciembre de 2022Empleo de X-Robots-Tags en su portal web
Entender y supervisar de qué forma los buscadores interaccionan con su ubicación es la piedra angular de la optimización de buscadores web. Y X-Robots-Tag es una vigorosa herramienta que puede emplear para llevar a cabo exactamente eso.
Observación: no está exenta de riesgos. Es muy simple cometer un fallo y desindexar su lugar.
Mencionado lo anterior, si lees este producto, probablemente no seas un novato en SEO. Siempre y cuando lo use de forma sabia, se tome su tiempo y compruebe su trabajo, hallará que X-Robots-Tag es una adición útil a su armamento.
Otros elementos:
Imagen señalada: Song_about_summer/Shutterstock
Fuente: searchenginejournal
Hashtags: #Todo #precisa #comprender #sobre #encabezado #HTTP #XRobotsTag
Comentarios recientes