Google plus anunció una búsqueda renovadora en el procesamiento del lenguaje natural llamada Chain of Thought Prompting, que eleva el estado del arte de tecnologías destacadas como PaLM y LaMDA a eso que los estudiosos llaman un nivel destacable.
Visto que Chain of Thought Prompting logre prosperar PaLM y LaMDA a estas tasas importantes es un enorme inconveniente.
LaMDA y PaLM
La investigación efectuó ensayos usando 2 modelos de lenguaje, el Modelo de lenguaje para apps de diálogo (LaMDA) y el Modelo de vías de lenguaje (PaLM).
LaMDA es un modelo pensado para la charla, como un chatbot, pero asimismo se puede utilizar para muchas otras apps que necesitan voz, diálogo.
PaLM es un modelo que prosigue lo que Google plus llama arquitectura Pathways AI, donde se adiestra un modelo de lenguaje para estudiar a solucionar inconvenientes.
Previamente, los modelos de estudio automático se entrenaban para solucionar un género de inconveniente y, fundamentalmente, se lanzaban para llevarlo a cabo realmente bien. Pero para llevar a cabo otra cosa, Google plus debería entrenar un nuevo modelo.
La arquitectura Pathways AI es una manera de crear un modelo que puede solucionar inconvenientes que no siempre vió antes.
Como se cita en la explicación de Google plus PaLM:
«… nos agradaría conformar un modelo que sea capaz no solo de llevar a cabo en frente de muchas tareas separadas, sino más bien asimismo de utilizar y conjuntar sus capacidades que ya están para estudiar novedosas ocupaciones de forma mucho más rápida y eficaz».
¿Qué haces?
El trabajo de investigación cuenta tres descubrimientos esenciales para el razonamiento en la cadena de pensamiento:
- Deja que los modelos lingüísticos dividan inconvenientes complejos de múltiples pasos en una secuencia de pasos.
- El desarrollo de cadena de pensamiento deja a los ingenieros echar una ojeada al desarrollo, y en el momento en que las cosas van mal, esto les deja detectar dónde salió mal y arreglarlo.
- Puede solucionar inconvenientes matemáticos verbales, puede llevar a cabo argumentos de los pies en el suelo y, según el trabajo de investigación, puede (de entrada) solucionar cualquier inconveniente apoyado en las expresiones que un individuo puede llevar a cabo.
Tareas de razonamiento de múltiples pasos
La investigación da un caso de muestra de una actividad de razonamiento de múltiples pasos donde se prueban modelos lingüísticos:
«P: La cantina tenía 23 manzanas. Si utilizaron 20 para el almuerzo y adquirieron 6 mucho más, ¿cuántas manzanas tienen?
A: La cantina en un inicio tenía 23 manzanas. Utilizaron 20 para elaborar el almuerzo. Conque tenían 23 – 20 = 3. Adquirieron 6 manzanas mucho más, conque tienen 3 + 6 = 9. La contestación es 9″.
PaLM es un modelo de lenguaje de nueva generación que pertenece a la arquitectura Pathways AI. Es tan adelantado que puede argumentar por qué razón un chiste es jocoso.
No obstante, da igual qué tan adelantado sea el PaLM, los estudiosos comentan que Chain of Thought Prompting optimización de manera significativa estos patrones y eso provoca que esta novedosa investigación sea tan digna de cuenta.
Google plus enseña:
«El pensamiento en cadena deja que los modelos descompongan inconvenientes complejos en pasos intermedios que se resuelven individualmente.
Además de esto, la naturaleza lingüística de la cadena de pensamiento la hace aplicable a cualquier labor que un individuo logre solucionar a través del lenguaje.
Las indagaciones siguen señalando que la indicación estándar no optimización verdaderamente en el momento en que se aproxima la escala del modelo.
No obstante, con este nuevo sentido, la escala tiene un encontronazo positivo importante y importante en el desempeño del modelo.
resultado
Chain of Thought Prompting se probó tanto en LaMDA como en PaLM, usando 2 conjuntos de datos con inconvenientes matemáticos.
Los estudiosos usan estos conjuntos de datos como una manera de equiparar desenlaces sobre inconvenientes afines para distintas modelos de lenguaje.
Ahora se detallan imágenes gráficas que detallan los desenlaces del empleo de Chain of Thought Prompting en LaMDA.
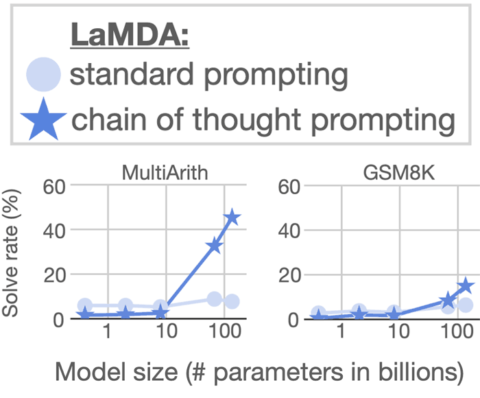
Los desenlaces del escalado de LaMDA en el grupo de datos MultiArith detallan una optimización modesta. Pero LaMDA puntúa relevantemente mucho más prominente en el momento en que se escala con Chain of Thought Prompting.
Los desenlaces del grupo de datos GSM8K detallan una optimización modesta.
La historia es diferente con el modelo lingüístico PaLM.
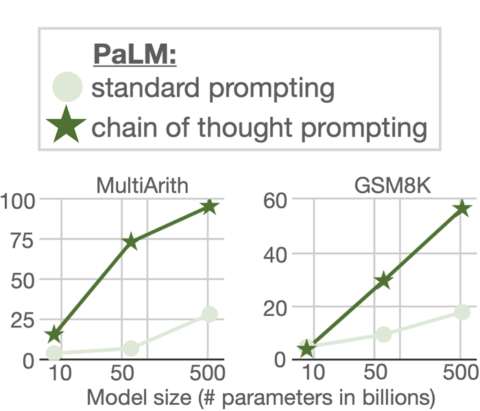
Como puede ver en el gráfico previo, las ganancias del escalado PaLM con Chain of Thought Prompting son gigantes y gigantes para los dos conjuntos de datos (MultiArith y GSM8K).
Los estudiosos definen los visibles desenlaces y un nuevo estado del arte:
“En el grupo de datos GSM8K de inconvenientes matemáticos, PaLM exhibe un desempeño inusual en el momento en que se escala a factores 540B.
… conjuntar la cadena de pensamiento con el modelo PaLM con el factor 540B lleva a un nuevo desempeño de vanguardia del 58%, superando el estado del arte previo en un 55% logrado al cambiar el GPT-3 175B en un entrenamiento riguroso detallar y después clasificar las probables resoluciones por medio de un verificador singularmente preparado.
Además de esto, el trabajo agregada sobre la autoconsistencia exhibe que el desempeño de la cadena de pensamiento se puede progresar aún mucho más al conseguir el voto mayoritario de un enorme grupo de procesos de razonamiento generados, con una precisión del 74 % en GSM8K. «
conclusiones
La conclusión de un trabajo de investigación se encuentra dentro de las partes mucho más esenciales para contrastar si la investigación avanza al estado del arte o está atascada o necesita mucho más investigación.
La sección de Google plus sobre los desenlaces de la búsqueda de documentos tiene una fuerte nota efectiva.
Nota:
«Exploramos la cadena de pensamiento como un procedimiento fácil y extensamente aplicable para progresar el razonamiento en modelos lingüísticos.
Mediante ensayos de razonamiento aritmético, simbólico y de los pies en el suelo, descubrimos que el procesamiento de la cadena de pensamiento es una propiedad nuevo de la escala del modelo que deja que los modelos lingüísticos sean suficientemente enormes para efectuar tareas de razonamiento que, de otra manera, tendrían curvas de escala plana.
Se estima que la expansión de la gama de tareas de razonamiento que tienen la posibilidad de efectuar los modelos de lenguaje inspire mucho más trabajo sobre enfoques de razonamiento basados en el lenguaje. «
Esto quiere decir que Chain of Thought Prompting tiene la posibilidad de tener el potencial de ofrecerle a Google plus la aptitud de prosperar relevantemente sus distintos modelos de lenguaje, lo que paralelamente puede conducir a actualizaciones importantes en los modelos de cosas que Google plus puede realizar.
mencionado
Lee el producto sobre la inteligencia artificial de Google plus
Los modelos lingüísticos llegan al razonamiento por medio de la cadena del pensamiento
Descarga y lee el trabajo de investigación
La cadena de advertencias de pensamiento establece el razonamiento en enormes modelos de lenguaje (PDF)
Fuente: searchenginejournal
Hashtags: #Google plus #Chain #Thought #Prompting #puede #alentar #los #mejores #algoritmos #el día de hoy
Comentarios recientes