En mi último producto, examinamos nuestros backlinks usando datos de Ahrefs.
En esta ocasión, nos encontramos introduciendo los vínculos de retroceso de los contendientes en nuestro análisis usando exactamente la misma fuente de datos de Ahrefs para cotejar.
Como la última vez, definimos el valor de vínculo de retroceso de un ubicación para SEO como un producto de calidad y cantidad.
La calidad es la autoridad del dominio (o la calificación de dominio semejante de Ahrefs) y la cantidad es el número de dominios de referencia.
De nuevo evaluaremos la calidad de la conexión con los datos libres antes de valorar la cantidad.
Es hora de codificar.
import re
import time
import random
import pandas as pd
import numpy as np
import datetime
from datetime import timedelta
from plotnine import *
import matplotlib.pyplot as plt
from pandas.api.types import is_string_dtype
from pandas.api.types import is_numeric_dtype
import uritools
pd.set_option('display.max_colwidth', None)
%matplotlib inline
root_domain = 'johnsankey.co.uk' hostdomain = 'www.johnsankey.co.uk' hostname="johnsankey" full_domain = 'https://www.johnsankey.co.uk' target_name="John Sankey"
Importa y limpia tus datos
Configuré directorios de ficheros para leer múltiples ficheros de datos exportados de Ahrefs en solo una carpeta, lo que es considerablemente más veloz, menos molesto y mucho más eficaz que leer cada fichero individual.
¡En especial en el momento en que tienes mucho más de 10 años!
ahrefs_path="data/"
La función listdir () en el módulo del S.O. nos deja enumerar todos y cada uno de los ficheros en un subdirectorio.
ahrefs_filenames = les.listdir(ahrefs_path)
ahrefs_filenames.remove('.DS_Store')
ahrefs_filenames
Archivo names now listed below:
['www.davidsonlondon.com--refdomains-subdomain__2022-03-13_23-37-29.csv',
'www.stephenclasper.co.uk--refdomains-subdoma__2022-03-13_23-47-28.csv',
'www.touchedinteriors.co.uk--refdomains-subdo__2022-03-13_23-42-05.csv',
'www.lushinteriors.co--refdomains-subdomains__2022-03-13_23-44-34.csv',
'www.kassavello.com--refdomains-subdomains__2022-03-13_23-43-19.csv',
'www.tulipinterior.co.uk--refdomains-subdomai__2022-03-13_23-41-04.csv',
'www.tgosling.com--refdomains-subdomains__2022-03-13_23-38-44.csv',
'www.onlybespoke.com--refdomains-subdomains__2022-03-13_23-45-28.csv',
'www.williamgarvey.co.uk--refdomains-subdomai__2022-03-13_23-43-45.csv',
'www.hadleyrose.co.uk--refdomains-subdomains__2022-03-13_23-39-31.csv',
'www.davidlinley.com--refdomains-subdomains__2022-03-13_23-40-25.csv',
'johnsankey.co.uk-refdomains-subdomains__2022-03-18_15-15-47.csv']
Con los ficheros enumerados, en este momento leeremos cada sujeto empleando un bucle for y los agregaremos a un marco de datos.
Mientras que leemos el fichero, vamos a usar ciertas manipulaciones de cadenas para hacer una exclusiva columna de nombre de ubicación para los datos que nos encontramos importando.
ahrefs_df_lst = list()
ahrefs_colnames = list()
for filename in ahrefs_filenames:
df = pd.read_csv(ahrefs_path + filename)
df['site'] = filename
df['site'] = df['site'].str.replace('www.', '', regex = False)
df['site'] = df['site'].str.replace('.csv', '', regex = False)
df['site'] = df['site'].str.replace('-.+', '', regex = True)
ahrefs_colnames.append(df.columns)
ahrefs_df_lst.append(df)
ahrefs_df_raw = pd.concat(ahrefs_df_lst)
ahrefs_df_raw
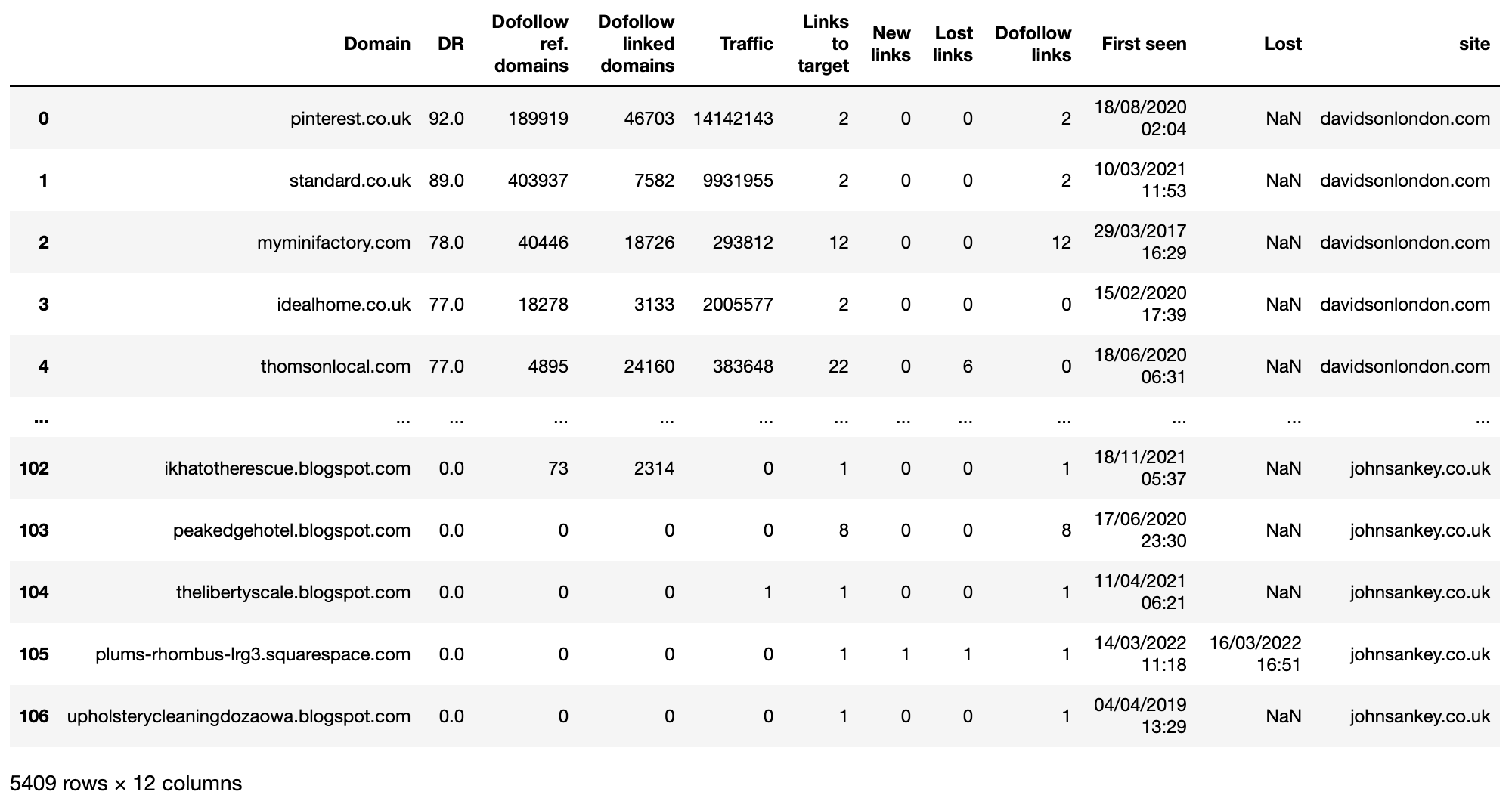
Imagen de Ahrefs, mayo de 2022
En este momento poseemos los datos sin procesar de cada lugar en un solo marco de datos. El próximo paso es ordenar los nombres de las columnas y lograr que sea un tanto mucho más simple trabajar con ellos.
Más allá de que la reiteración se puede remover con una función adaptada o una lista de tareas atentos, es buena práctica y mucho más simple para los Pythonistas de SEO principiantes ver lo que ocurre pasito a pasito. Como dicen, «la reiteración es la madre de la maestría», ¡conque ejerce!
competitor_ahrefs_cleancols = ahrefs_df_raw
competitor_ahrefs_cleancols.columns = [col.lower() for col in competitor_ahrefs_cleancols.columns]
competitor_ahrefs_cleancols.columns = [col.replace(' ','_') for col in competitor_ahrefs_cleancols.columns]
competitor_ahrefs_cleancols.columns = [col.replace('.','_') for col in competitor_ahrefs_cleancols.columns]
competitor_ahrefs_cleancols.columns = [col.replace('__','_') for col in competitor_ahrefs_cleancols.columns]
competitor_ahrefs_cleancols.columns = [col.replace('(','') for col in competitor_ahrefs_cleancols.columns]
competitor_ahrefs_cleancols.columns = [col.replace(')','') for col in competitor_ahrefs_cleancols.columns]
competitor_ahrefs_cleancols.columns = [col.replace('%','') for col in competitor_ahrefs_cleancols.columns]
La columna de recuento y la columna de valor único («emprendimiento») son útiles para operaciones de agrupación y agregación.
competitor_ahrefs_cleancols['rd_count'] = 1 competitor_ahrefs_cleancols['project'] = target_name competitor_ahrefs_cleancols
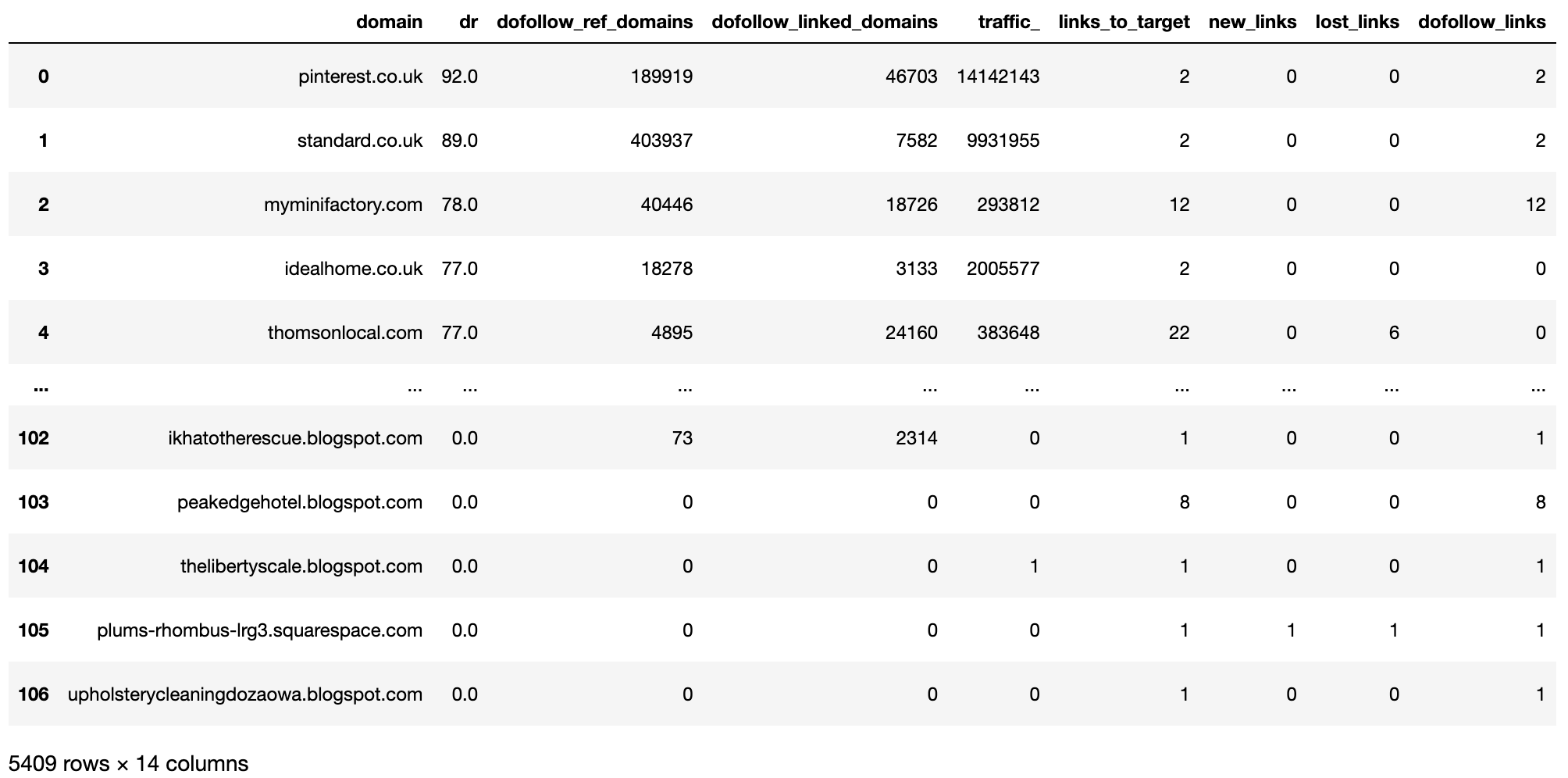 Imagen de Ahrefs, mayo de 2022
Imagen de Ahrefs, mayo de 2022Las columnas se están limpiando, conque en este momento vamos a adecentar los datos regulares.
competitor_ahrefs_clean_dtypes = competitor_ahrefs_cleancols
Para los campos de referencia, sustituimos los guiones con cero y establecemos el género de datos en un número entero (esto es, un número entero).
Esto se va a repetir para las áreas similares.
competitor_ahrefs_clean_dtypes['dofollow_ref_domains'] = np.where(competitor_ahrefs_clean_dtypes['dofollow_ref_domains'] == '-', 0, competitor_ahrefs_clean_dtypes['dofollow_ref_domains']) competitor_ahrefs_clean_dtypes['dofollow_ref_domains'] = competitor_ahrefs_clean_dtypes['dofollow_ref_domains'].astype(int) # linked_domains competitor_ahrefs_clean_dtypes['dofollow_linked_domains'] = np.where(competitor_ahrefs_clean_dtypes['dofollow_linked_domains'] == '-', 0, competitor_ahrefs_clean_dtypes['dofollow_linked_domains']) competitor_ahrefs_clean_dtypes['dofollow_linked_domains'] = competitor_ahrefs_clean_dtypes['dofollow_linked_domains'].astype(int)
La primera vista nos ofrece un punto donde se hallaron los links, que tenemos la posibilidad de utilizar para marcar la serie temporal y derivar la edad de los links.
Convertiremos al formato de fecha empleando la función to_datetime.
# first_seen
competitor_ahrefs_clean_dtypes['first_seen'] = pd.to_datetime(competitor_ahrefs_clean_dtypes['first_seen'],
format="%d/%m/%Y %H:%M")
competitor_ahrefs_clean_dtypes['first_seen'] = competitor_ahrefs_clean_dtypes['first_seen'].dt.normalize()
competitor_ahrefs_clean_dtypes['month_year'] = competitor_ahrefs_clean_dtypes['first_seen'].dt.to_period('M')
Para calcular link_age, sencillamente inferiremos la primera oportunidad que lo hemos visto el día de hoy y convertiremos la diferencia en un número.
# backlink age competitor_ahrefs_clean_dtypes['link_age'] = dt.datetime.now() - competitor_ahrefs_clean_dtypes['first_seen'] competitor_ahrefs_clean_dtypes['link_age'] = competitor_ahrefs_clean_dtypes['link_age'] competitor_ahrefs_clean_dtypes['link_age'] = competitor_ahrefs_clean_dtypes['link_age'].astype(int) competitor_ahrefs_clean_dtypes['link_age'] = (competitor_ahrefs_clean_dtypes['link_age']/(3600 * 24 * 1000000000)).round(0)
La columna de destino nos asiste a distinguir el ubicación del «cliente» de los contendientes, lo que es útil para verlo después.
competitor_ahrefs_clean_dtypes['target'] = np.where(competitor_ahrefs_clean_dtypes['site'].str.contains('johns'),
1, 0)
competitor_ahrefs_clean_dtypes['target'] = competitor_ahrefs_clean_dtypes['target'].astype('category')
competitor_ahrefs_clean_dtypes
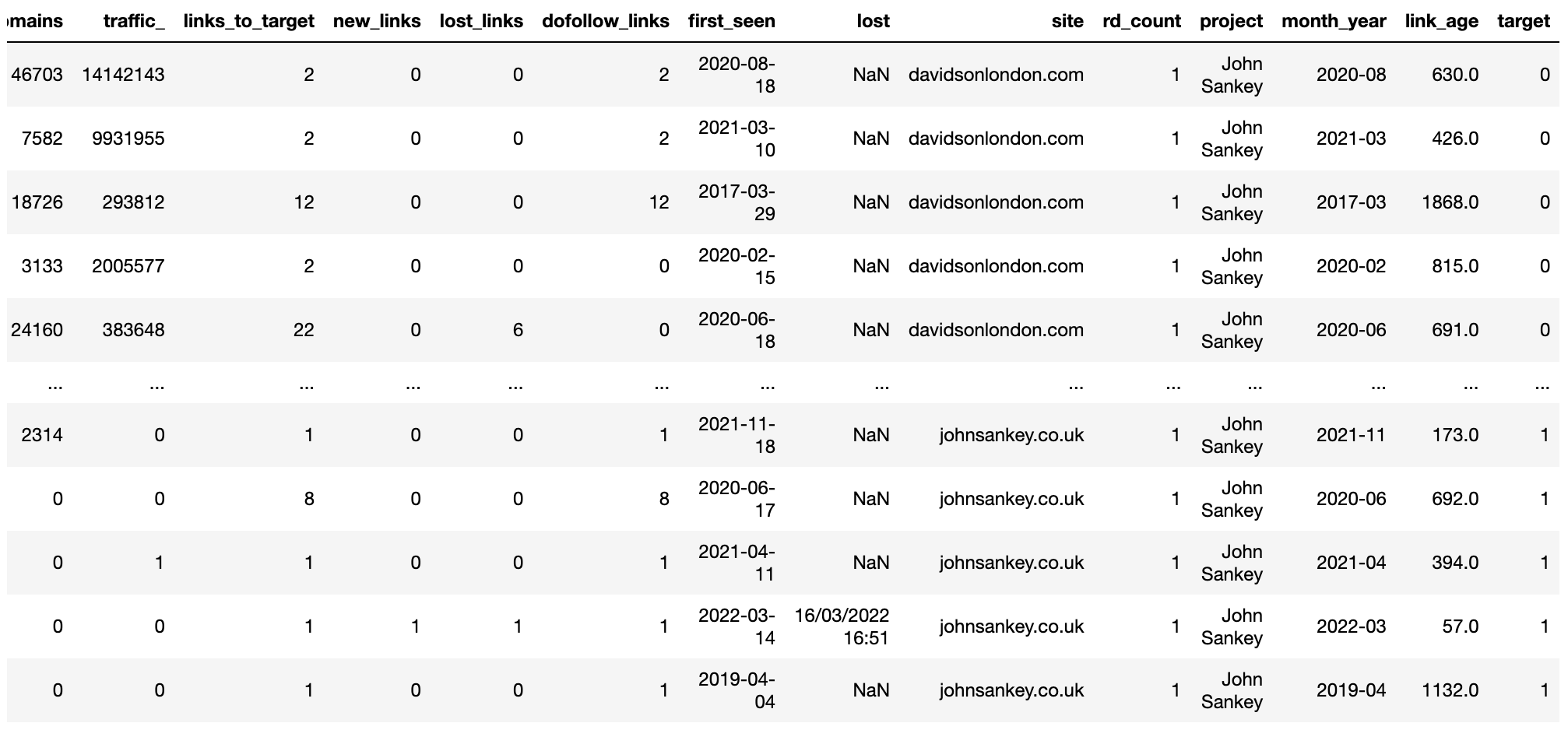 Imagen de Ahrefs, mayo de 2022
Imagen de Ahrefs, mayo de 2022En este momento que los datos se han eliminado en concepto de encabezados de columna y valores de fila, nos encontramos preparados para empezar a investigar.
La calidad del link
Empecemos con la calidad del link, que admitiremos como una medida de calificación de dominio (DR).
Empecemos por examinar las características distributivas de DR al graficar su distribución utilizando la función geom_bokplot.
comp_dr_dist_box_plt = ( ggplot(competitor_ahrefs_analysis.loc[competitor_ahrefs_analysis['dr'] > 0], aes(x = 'reorder(site, dr)', y = 'dr', colour="objetivo")) + geom_boxplot(alpha = 0.6) + scale_y_continuous() + theme(legend_position = 'none', axis_text_x=element_text(rotation=90, hjust=1) )) comp_dr_dist_box_plt.save(filename="images/4_comp_dr_dist_box_plt.png", height=5, width=10, units="in", dpi=1000) comp_dr_dist_box_plt
 Imagen de Ahrefs, mayo de 2022
Imagen de Ahrefs, mayo de 2022El gráfico equipara las características estadísticas del lugar una a la vera de la otra y, particularmente, el rango intercuartílico que exhibe dónde están la mayor parte de los dominios de referencia en concepto de evaluación de dominio.
Asimismo observamos que John Sankey tiene la cuarta calificación promedio mucho más alta en el dominio, lo que se equipara bien con la calidad de los links a otros sitios.
William Garvey tiene la gama mucho más extensa de DR que otros dominios, lo que señala un método levemente mucho más relajado para obtener links. Quién sabe.
Volumen de link
Esta es la calidad. ¿Qué sucede con el volumen de links de dominios de referencia?
Para solucionar este inconveniente, calcularemos una cantidad de hoy de dominios de referencia usando la función groupby.
competitor_count_cumsum_df = competitor_ahrefs_analysis competitor_count_cumsum_df = competitor_count_cumsum_df.groupby(['site', 'month_year'])['rd_count'].sum().reset_index()
La función de extensión deja que el papel de cálculo aumente con el número de filas, y es de este modo como llegamos a la cantidad de hoy.
competitor_count_cumsum_df['count_runsum'] = competitor_count_cumsum_df['rd_count'].expanding().sum() competitor_count_cumsum_df
 Imagen de Ahrefs, mayo de 2022
Imagen de Ahrefs, mayo de 2022El resultado es un marco de datos con el ubicación, month_year y count_runsum (cantidad de hoy), que tiene el formato idóneo para dar de comer el gráfico.
competitor_count_cumsum_plt = ( ggplot(competitor_count_cumsum_df, aes(x = 'month_year', y = 'count_runsum', group = 'site', colour="site")) + geom_line(alpha = 0.6, size = 2) + labs(y = 'Running Sum of Referring Domains', x = 'Month Year') + scale_y_continuous() + scale_x_date() + theme(legend_position = 'right', axis_text_x=element_text(rotation=90, hjust=1) ))
competitor_count_cumsum_plt.save(filename="images/5_count_cumsum_smooth_plt.png", height=5, width=10, units="in", dpi=1000) competitor_count_cumsum_plt
 Imagen de Ahrefs, mayo de 2022
Imagen de Ahrefs, mayo de 2022El gráfico exhibe el número de dominios de referencia para cada ubicación en 2014.
Acercamiento que las distintas situaciones iniciales para cada lugar son bastante atrayentes en el momento en que empiezan a obtener links.
Por poner un ejemplo, William Garvey empezó con mucho más de 5000 dominios. ¡Me encantaría entender quién es su agencia de relaciones públicas!
Asimismo podemos consultar la tasa de desarrollo. Por poner un ejemplo, si bien Hadley Rose empezó a obtener corbatas en 2018, las cosas verdaderamente han comenzado en la época de 2021.
Mucho más, cada vez más
Puede realizar múltiples análisis científicos cualquier ocasión.
Por poner un ejemplo, una extensión instantánea y natural de lo previo sería conjuntar calidad (DR) y cantidad (volumen) para conseguir una visión mucho más holística de la comparación entre sitios en concepto de SEO de afuera.
Otras extensiones modelarían las características de esos dominios de referencia tanto para su ubicación para los sitios de la rivalidad, para poder ver qué especificaciones del link (como la proporción de expresiones o la importancia del contenido del link) podrían argumentar la diferencia de visibilidad entre usted y su contendientes.
Esta extensión del modelo sería una aceptable app de estas técnicas de estudio automático.
Mucho más elementos:
Imagen mostrada: Estudio F8/Shutterstock
Fuente: searchenginejournal
Hashtags: #Análisis #backlinks #simultaneidad #Python #Complete #Script
Comentarios recientes